Greetings, fellow data wardens. Structure on read is particularly powerful for security use cases like tcp-over-dns tunneling. We first extract the DNS information, isolate the payloads, strip away the DNS layers, and treat the payloads as if they were raw packets. It's really cool! For this post, we're talking about something a little more common: csv over syslog messages.
First, rather than use specific data or try and pick a particular technology to demonstrate this, let's just generate some ourselves using the `logger` tool that's present on most linux distros. With `logger` you can manually generate syslog messages. Let's imagine we have a service that tracks our pets. We might have a format like:
pet,type,action
Let's generation some examples by issuing logger commands like:
`logger rover,dog,tailchasing`
`logger fluffy,cat,sleeping`
With some data generated, we move over to Gravwell for the analysis. Syslog extractions are pretty straightforward using the `syslog` module. I can look at all of my generated messages with a basic extraction | table query like this:
tag=syslog syslog Timestamp Appname==remasis Message | table
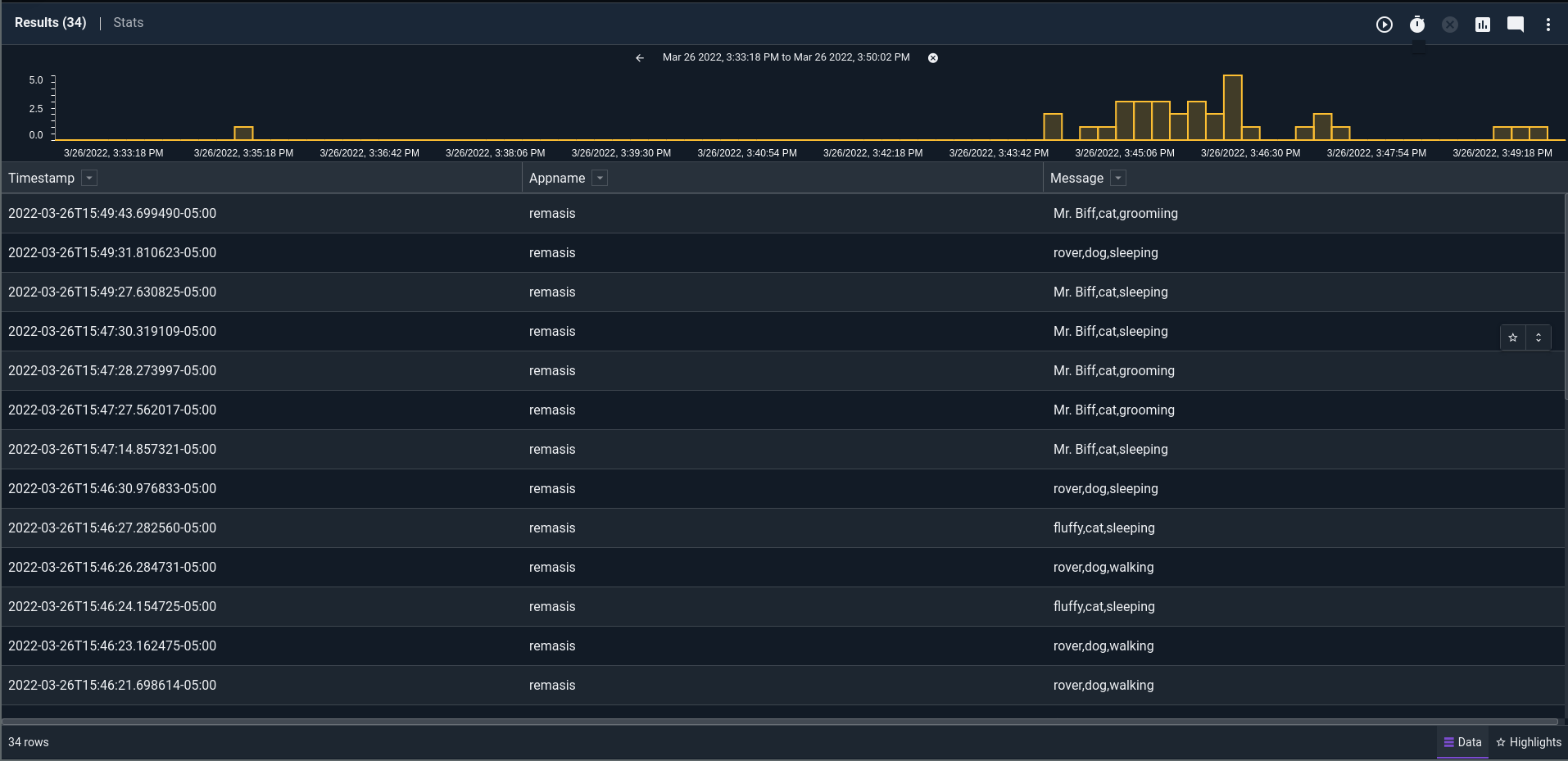
Note: the "appname==remasis" filter is to isolate only message I created for this example using the logger tool.
Note2: the logger tool will be "helpful" and may say "Message repeated [x] times". If you want to filter this out, prepend your query with a `grep -v "repeated"` module. Handling that type of data is also possible with structure on read (but it's behond the scope of this article).
We see that the data we actually want to look at is in the "Message" column, or in Gravwell search parlance, the "Message" enumerated value. These enumerated values flow alongside the raw data as it makes it's way through the analysis pipeline. We can operate on these enumerated values just like we can on the raw data. By adding in only one additional module, we can operate on only the csv fields we care about and forget that syslog was the medium in which we received them. Let's use the `csv` extraction module to get to the fields we want:
tag=syslog syslog Timestamp Appname==remasis Message
| csv -e Message pet type action
| table Timestamp pet type action
The powerful "-e" switch is one of the universal switches for Gravwell modules that tells it to work on a specific enumerated value and not on the raw data.
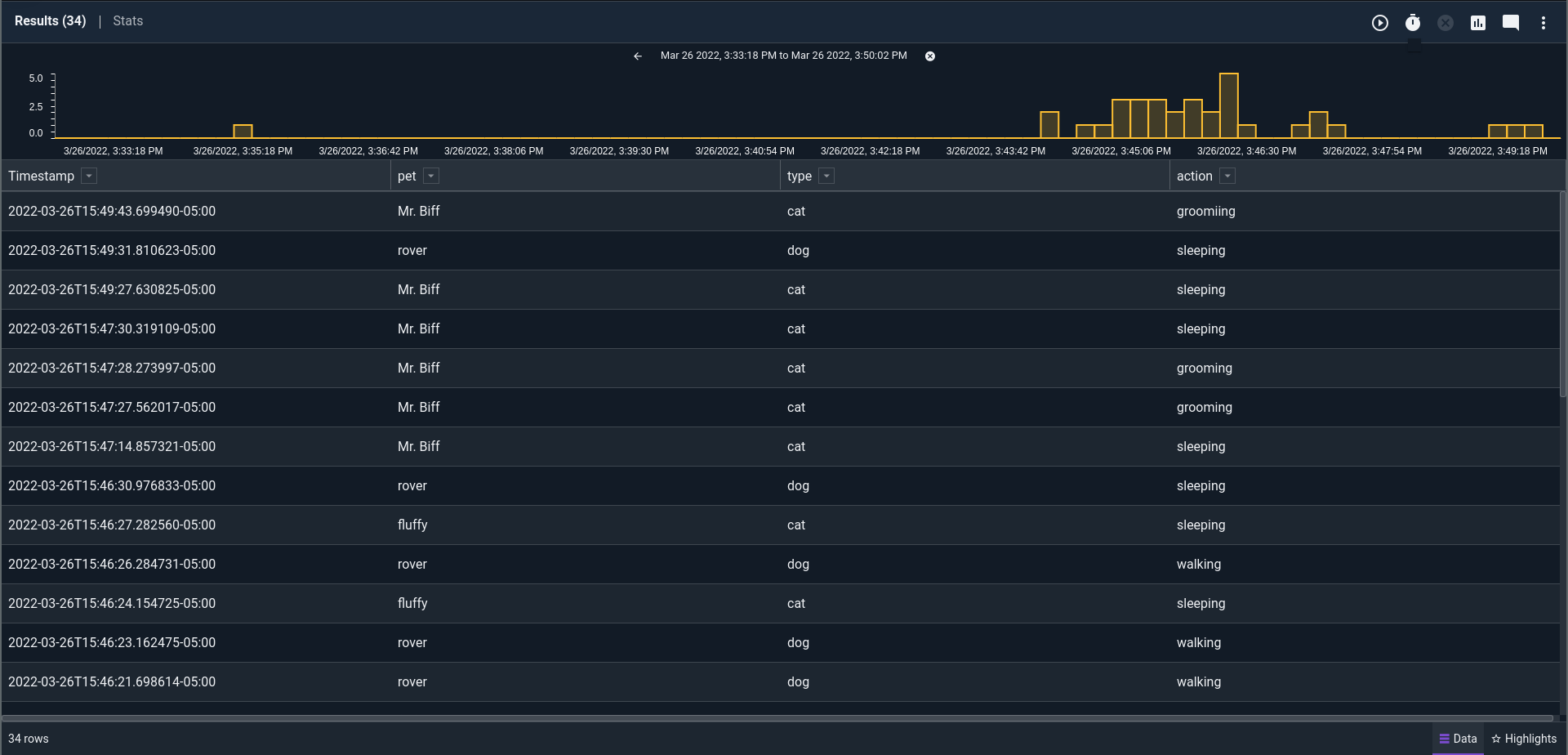
Now we're down to only the data we care about. If I was doing this frequently in a production environment, I would take the bulk of this query and turn it into a macro. 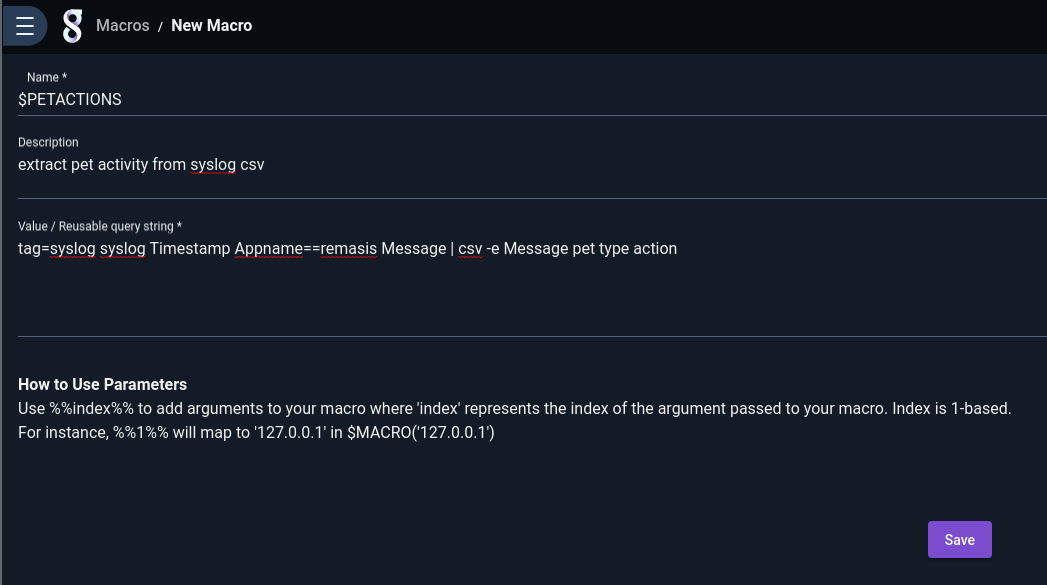
Now I can get to where I just was by issuing a simple search of `$PETACTIONS | table Timestamp pet type action`.
There are no limits to the analysis that can be done from this point, now that the data fields are extracted and ready for use. Let's show a chart of pet activity:
$PETACTIONS
| count by pet type action
| stackgraph pet type action
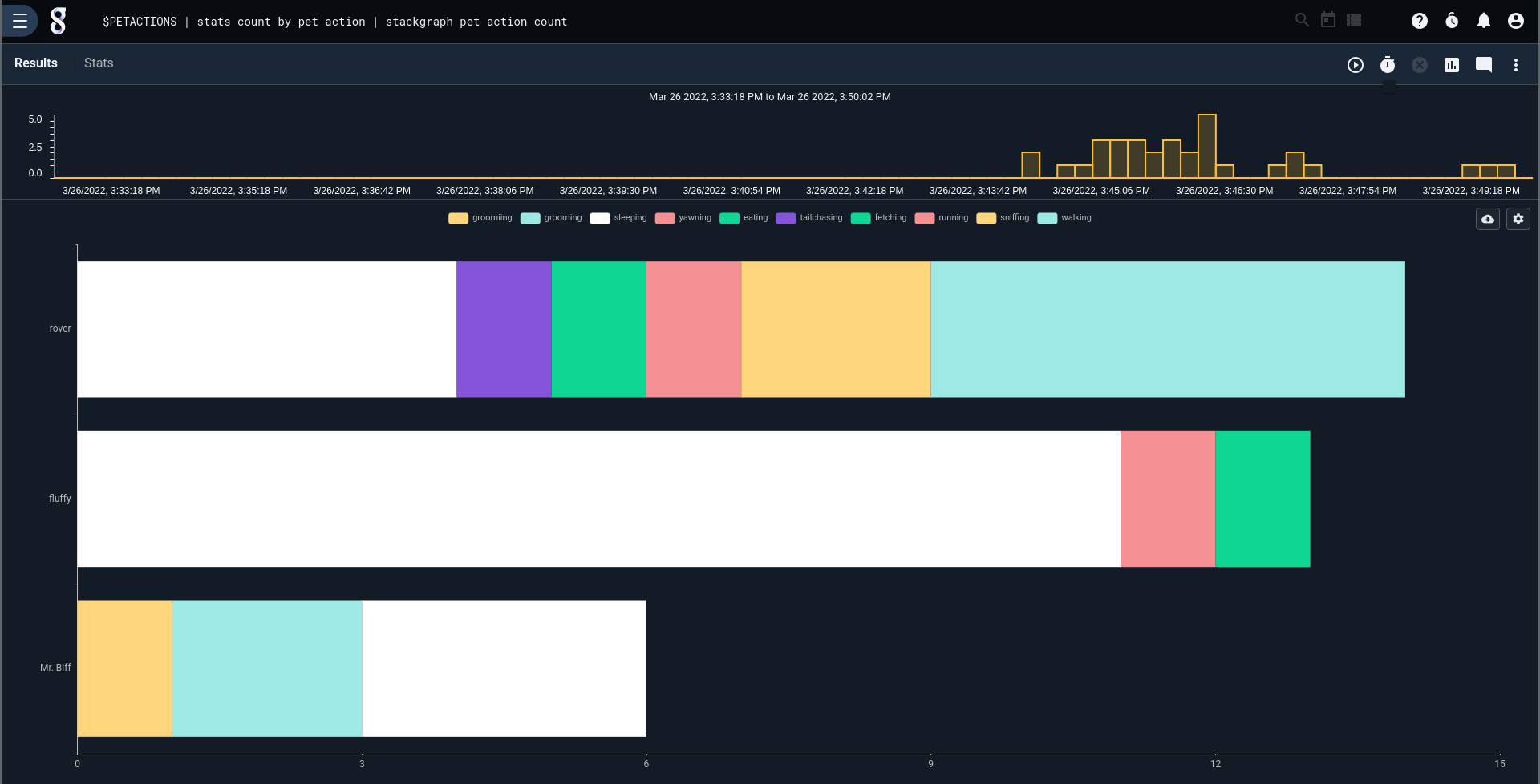
Perhaps we're interested not in an individual pet, but activity by pet type:
$PETACTIONS
| stats count by type action
| stackgraph type action count
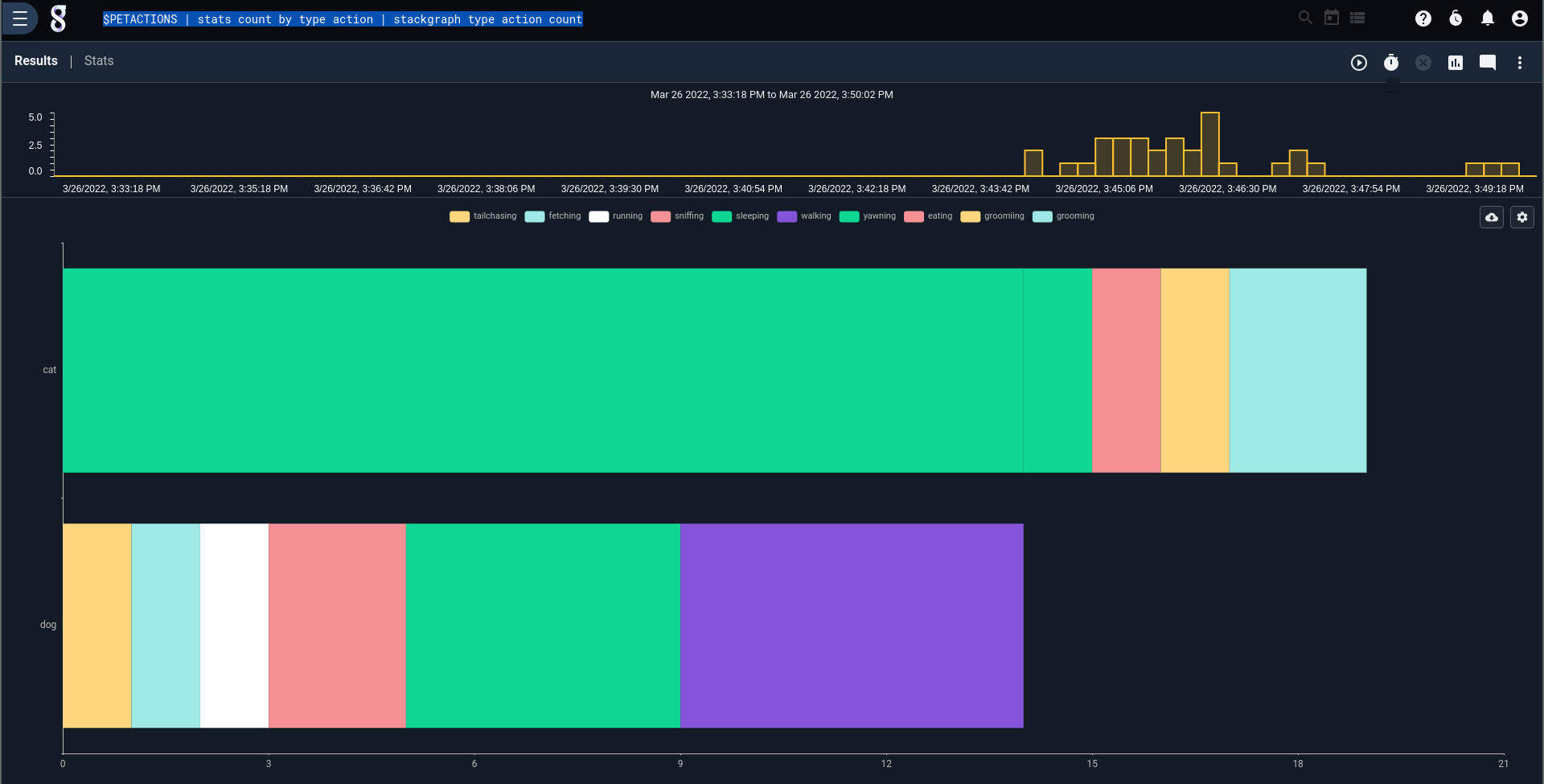
Those lazy, lazy cats.....
That's it for this short article. Structure-on-read makes it easy to collect data in ANY format, set up some extractors, and get to analyzing. There's no worry about data that doesn't fit our exact csv model -- we still capture it and can analyze using slightly different queries. That's what's crucial to responding to operations issues like stack traces hitting your log files or advanced cybersecurity analysis like the aforementioned tcp-over-dns exfiltation tunneling.
Happy hunting!