Blog

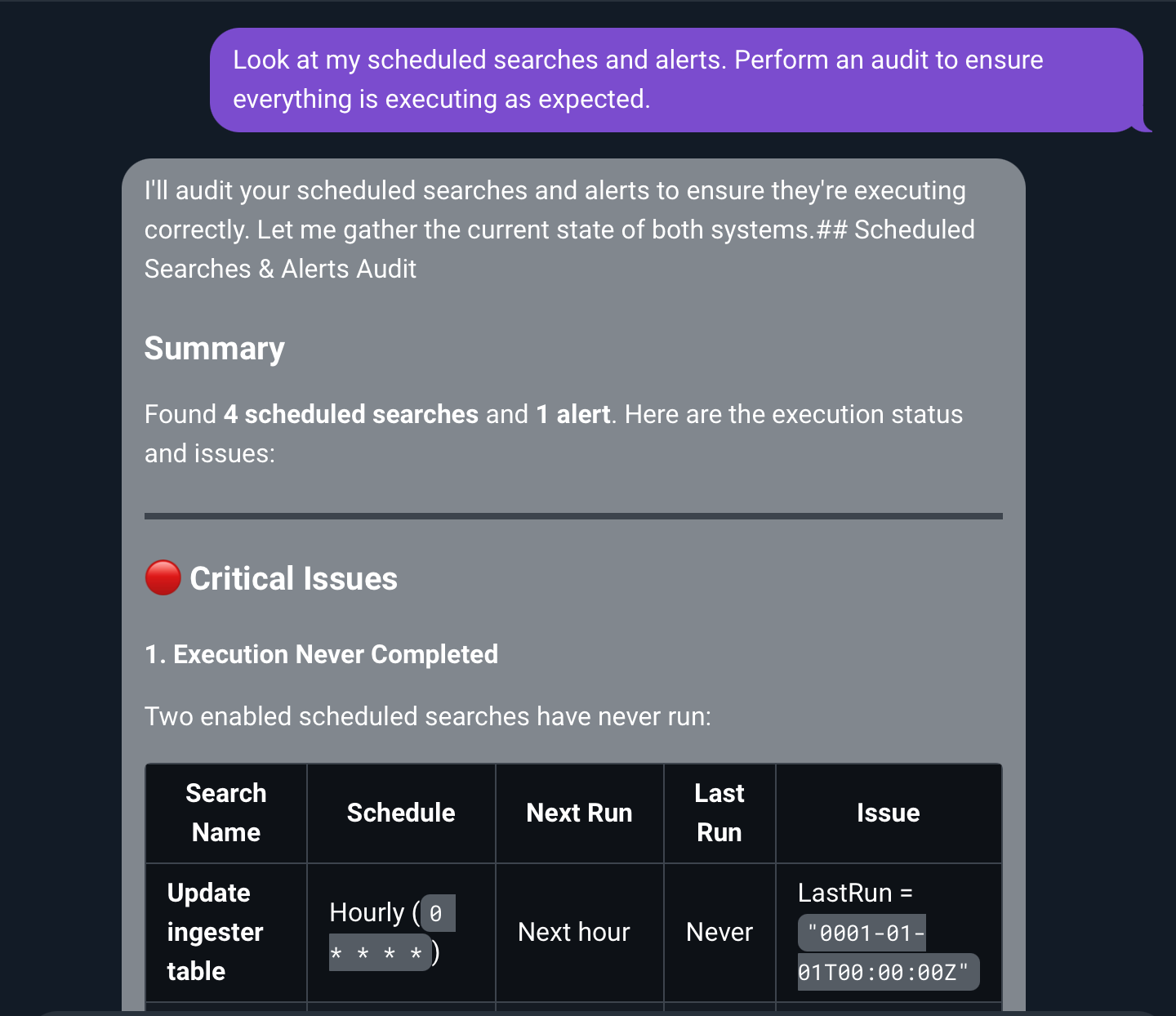
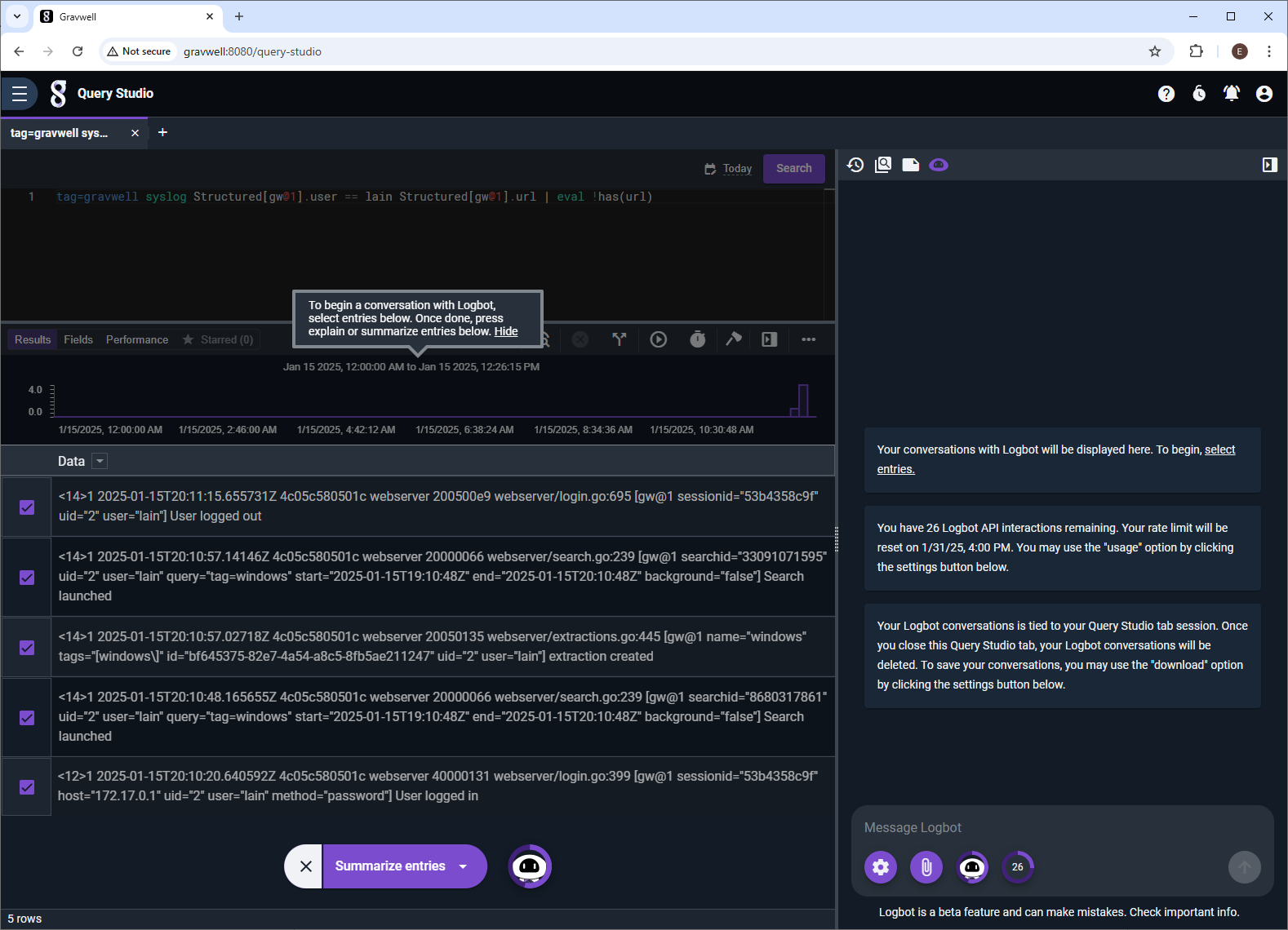
Today, we’re excited to announce a new and improved Logbot, Gravwell’s AI-powered security data assistant, as part of Gravwell v5.9. The release adds deeper platform integration, faster natural-language investigation workflows, instant playbook and automation generation, and bidirectional AI integrations through MCP. These upgrades bring AI-driven assistance directly into daily workflows, helping practitioners get to answers faster and do more with complex security data.