Thanks to Gravwell's Google PubSub ingester, it's easy to collect logs and other data from services deployed in the Google Cloud Platform. In this blog post, we'll show how to set up Gravwell in GCP and ingest system logs from your virtual machines.
Installing Gravwell
Installing Gravwell in a Google Compute Engine VM is exactly like installing on any other server. Simply copy the Gravwell installer file to the VM and run it.
When setting up the virtual machine, we recommend a few standard settings:
- Make sure to allow HTTP and HTTP traffic
- We suggest a standard Debian image (the default in GCP at this time)
- A slightly more powerful VM will yield more satisfying performance; we used n1-standard-4 (4 vCPUs, 15 GB memory) for this.
Once you've booted the VM and run the installer, you can point your browser at your VM's external IP and log in with the default username/password ("admin/changeme"). Be sure to change these immediately.
Creating a PubSub Topic
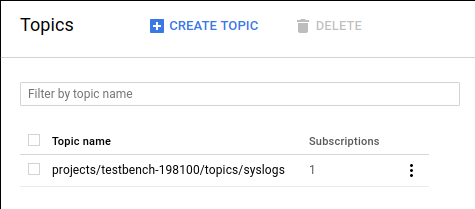
Before we begin ingesting from PubSub, we want to create a PubSub topic. Open the Google Cloud Platform console and under the "Big Data" section, select "PubSub". Then simply use the "Create Topic" button to make a new PubSub topic; we named ours "syslogs".
Installing the PubSub Ingester
Now that we've created a PubSub topic, we'll set up the PubSub ingester to fetch from it. You'll need a credentials file for your GCP account; visit the GCP credentials page, download the JSON file, and upload it to your Gravwell VM (we'll assume it's in /opt/gravwell/etc/my-credentials.json)
First, get the latest PubSub ingester from the Gravwell download page and copy it to your Gravwell VM, then unpack and install it:
tar xjvf gravwell_pubsub_ingest_installer_2.0.3.tar.bz2
sudo bash gravwell_pubsub_ingest_installer_2.0.3.shNow we need to edit the /opt/gravwell/etc/pubsub_ingest.conf configuration file to point at our GCP project and PubSub topic. The following shows a minimal configuration for our setup:
[Global]
Ingest-Secret = CHANGEME
Cleartext-Backend-target=127.0.0.1:4023
Log-Level=ERROR #options are OFF INFO WARN ERROR
# The GCP project ID to use
Project-ID="testbench-198100"
Google-Credentials-Path=/opt/gravwell/etc/my-credentials.json
[PubSub "gravwell"]
Topic-Name=syslogs # the pubsub topic you want to ingest
Tag-Name=gcp
Parse-Time=false
Assume-Localtime=trueThis will ingest a PubSub topic "syslogs" in the project "testbench-198100" using the credentials in /opt/gravwell/etc/my-credentials.json. Note that you'll need to refer to /opt/gravwell/etc/gravwell.conf to find the appropriate Ingest-Secret value, as this is randomly set when Gravwell is installed.
With the configuration file edited, we can start the PubSub ingester service:
service gravwell_pubsub_ingest restartIf you go to the Remote Ingesters tab in your Gravwell web UI's System Stats page, you should see the ingester listed.
Sending Logs to PubSub
Now that Gravwell is listening, we can send some logs to the PubSub topic. We chose to spin up a separate VM named log-generator, representing a system running some other service for your company.
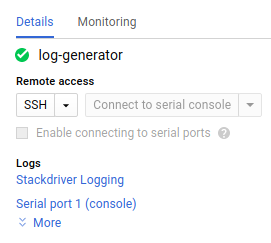
Within the VM's profile, we select Stackdriver Logging:
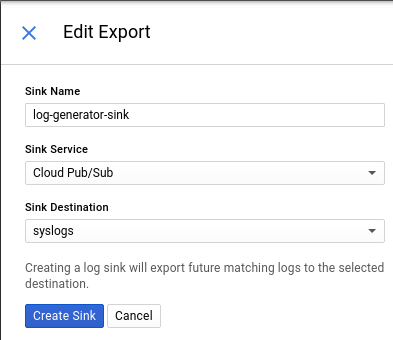
And then use the "Create Export" on the next page to export that VM's logs to our PubSub stream:
With that configured, we simply log into the new VM and install Google's logging agent
curl -sSO "https://dl.google.com/cloudagents/install-logging-agent.sh"
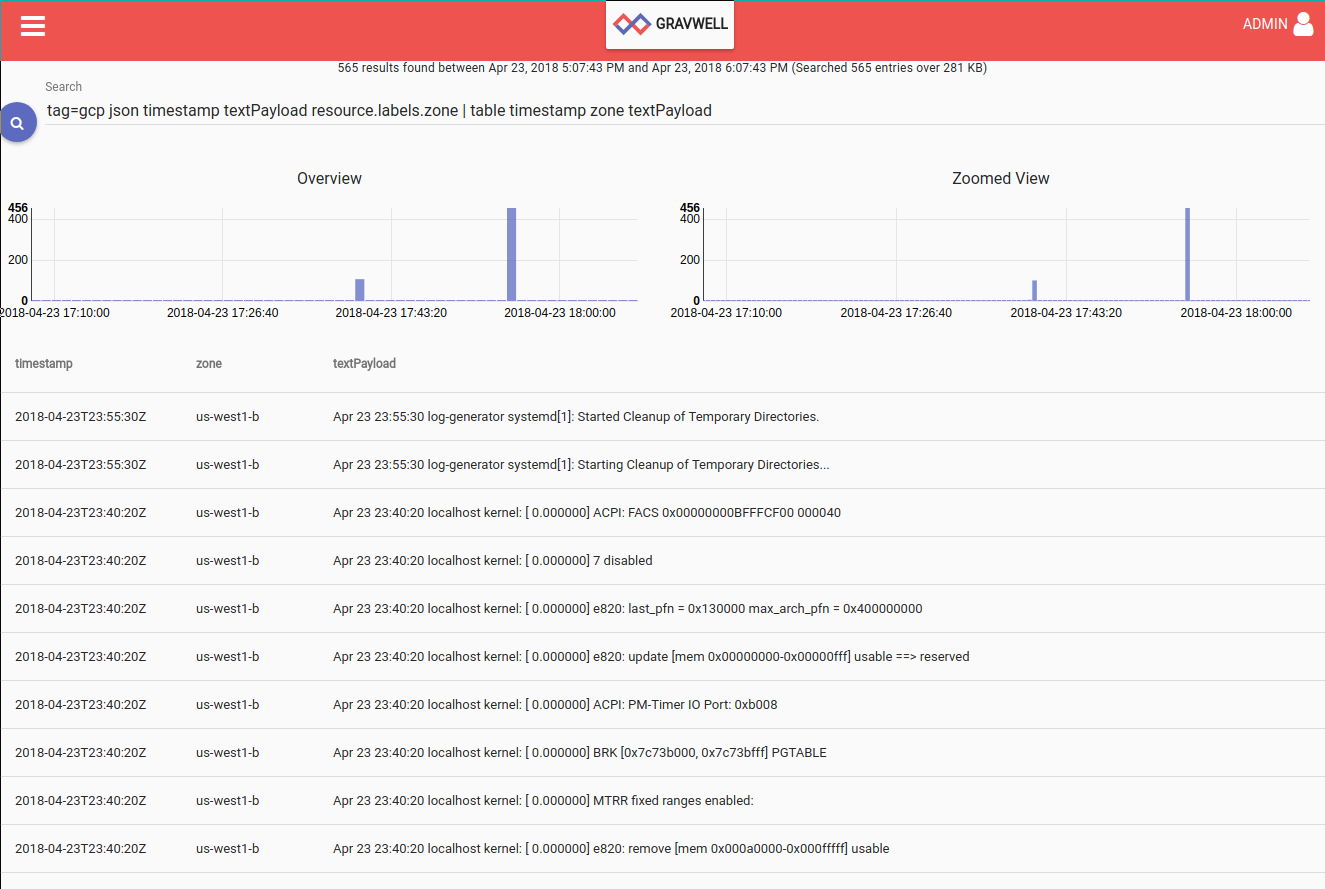
sudo bash install-logging-agent.shThis will send system logs to PubSub, which will in turn be ingested by Gravwell. We can issue a search in Gravwell using the "gcp" tag and find the entries, which are JSON-encoded and can be easily extracted into individual fields:
Summary
Gravwell in Google Cloud Platform allows you to easily aggregate and search all your data from all your VMs. Many services and applications with GCP export via PubSub; you can use different tags to organize data within your Gravwell instance. Contact us for more information about how Gravwell can help you monitor your cloud deployments!