This personal story I'm about to tell highlights one of the most important differentiators between Gravwell vs Splunk -- a non-abusive pricing model. Data rates aren't always predictable….
In early August, one of our ISPs went down for a few days, severing connectivity through their route. The Gravwell office has redundant providers that we test periodically, so there weren't any infrastructure connectivity issues. However, to complicate things more we had a large customer deployment happening that week so we were short staffed in the office and didn't really have people or time to fight an ISP when the redundant connectivity was still working. After we got some breathing room later in the week I pulled up the Gravwell dashboards for review and noticed something odd.
The number of netflow records was way above normal for the week. The next step involved finding out what all of these netflow records were about. After running a query to table up the flow records by source subnet, destination IP, and port, it becomes easy to see the culprit -- DNS.
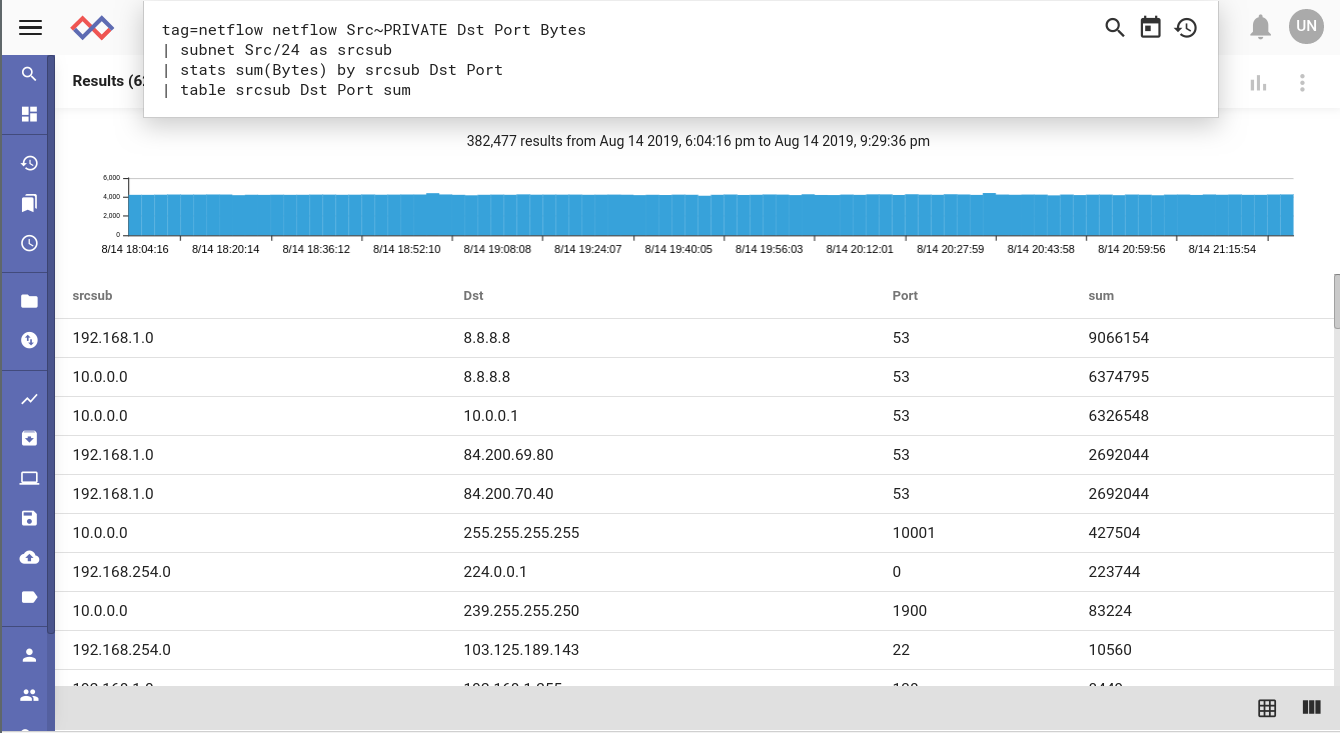
We're using syslog to log all of our DNS requests out of the office so the next step was to see if correlation between logs exists for this incident. Doing a quick Gravwell search I saw the same happened with syslog. This kind of occurrence is not at all rare and if we were a large enterprise the potential for data deluge would be even greater.
If we were stuck on some archaic, abusive pricing model that charged us for every entry or every byte that got ingested into our analytics tool, we'd have blown our quota already! This is completely unacceptable as data rates continue to increase. Surge allowances are a band-aid to this symptom, but they don't address the disease. If we hadn't noticed this during a surge window, we potentially start dropping data -- a cardinal sin.
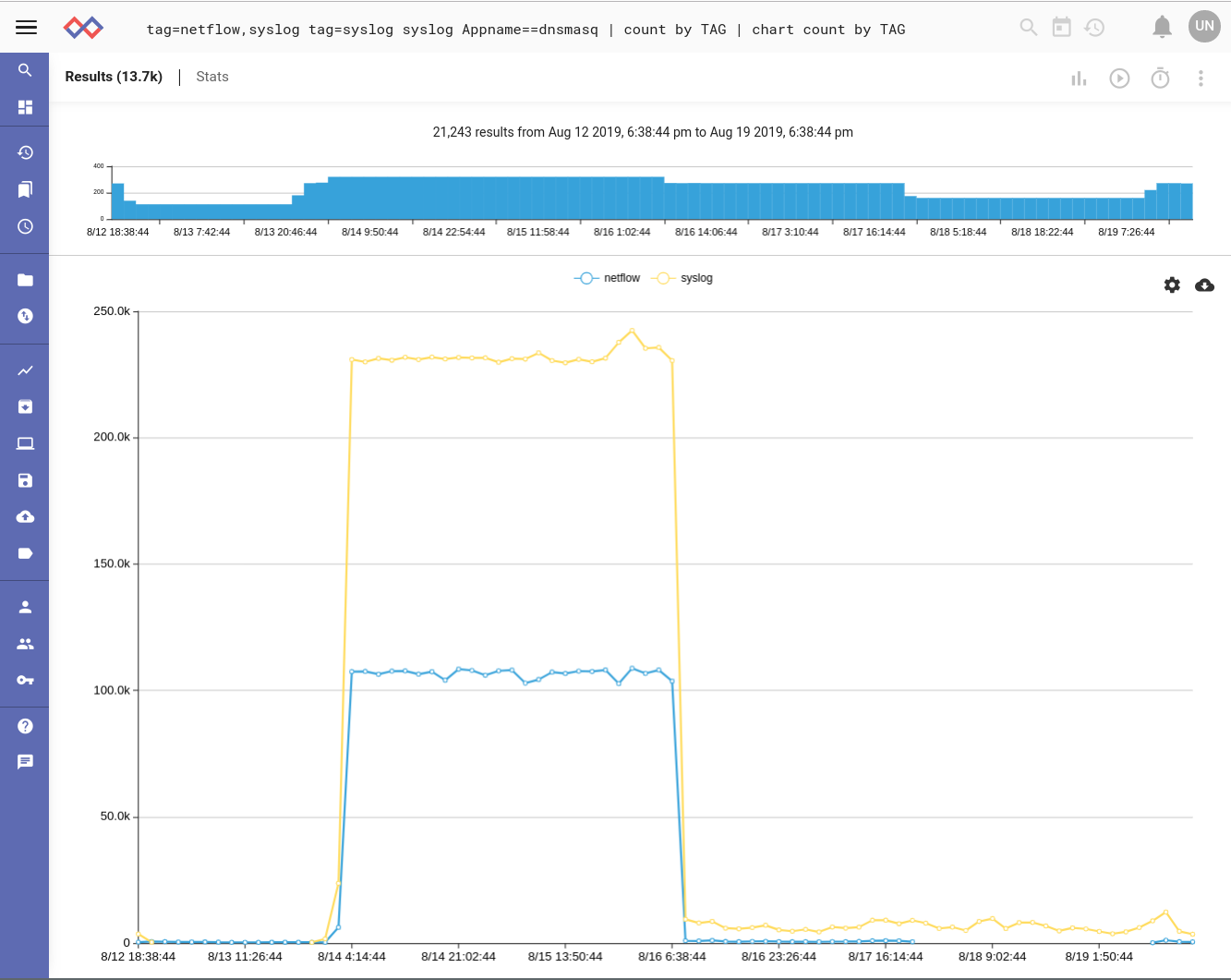
Sidenote: This query uses the very simplest Data Fusion capabilities to drop multiple data sources in the pipeline, operate on some of them, and create an aggregate. In this case we're just filtering on the syslog data to grab only DNS, but this is a super powerful feature that's extremely useful for enhancing context and extending situational awareness. Data Fusion has significant benefits over subqueries, which is how sophisticated queries using multiple data sources is usually done in analytics tools that lack this new tech. That's a different post for a different day.
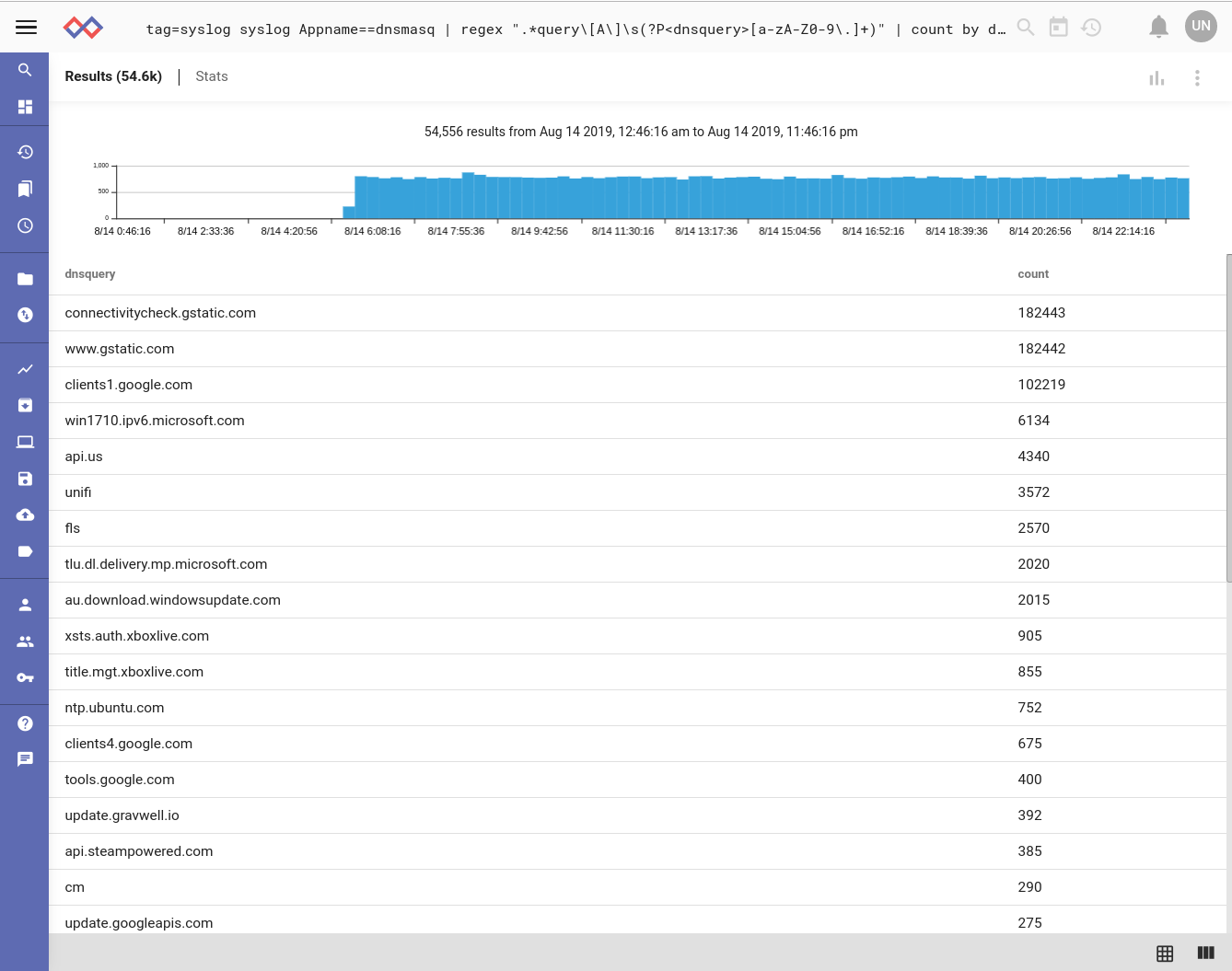
Digging directly into the syslog to identify the actual DNS queries, we start to get a picture about what's happening here. Thanks, Google:
One final change of the query to include the source IP address and then fuse in the hostnames extracted from DHCP ACK messages leads us to the culprits -- chromecast devices.
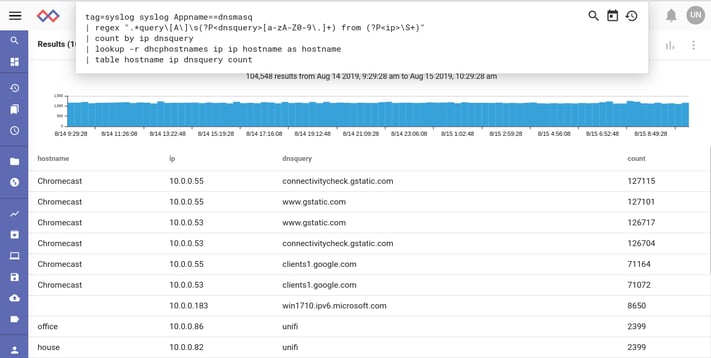
We observed that if a chromecast device cannot route to the Internet but can still query the DNS servers, it attempts to check connectivity many times per second.
This investigation led us to correct some network routing so that the chromecast devices stop spamming our DNS. We also created some Gravwell automation around the ingestion rates to create notifications when they change in a statistically significant manner (some people call this basic basline+anomalous detection "AI" but let's be honest it's fairly straightforward statistics).
I'm excited to see other startups in this space adopt a new pricing model. Though we think scaling based on nodes works better than scaling based on employees at a company or some other metric of size. You wouldn't expect VMWare to charge you based on how many virtual machines you run or how many people work at your company. Cloud computing is based on usage, but once you purchase that usage, you are free to do as you will.
That's what we're doing here at Gravwell. We are freeing you from license rate shackles. We're removing internal conflicts about whose data makes it into the analytics or how long they get to keep it. We're shattering the data caps and helping you focus on your mission. No one wants to fight unpredictable and expensive licensing fees. Go unlimited, go Gravwell.
