It’s Thanksgiving Weekend in America and that means most people have acknowledged the blessings in their lives and are gearing up for something America does better than anyone: consumerism. I had a bit of down time and thought I’d do something else America is good at: Freedom Fighting.
Net neutrality is back in the news and social media with the announcements coming out of the FCC this week. One article caught my interest because they mentioned some data points about the FCC comments (which we previously analyzed in detail).
This article claims to have an FCC insider giving statistics about the legitimacy of the comments.
“The vast majority of comments consisted of form letters from both pro- and anti-net neutrality groups and generally did not introduce new facts into the record or make serious legal arguments, the official from Pai's office said. In general, the comments stated opinions or made assertions and did not have much bearing on Pai's decision, the official said. The official spoke with reporters on the condition that he not be named and that his comments can be paraphrased but not quoted directly.
The official noted that many of the comments are fraudulent. He said that there were 7.5 million identical comments that came from 45,000 unique names and addresses, apparently due to a scammer who repeatedly submitted the same comment under a series of different names.” (emphasis added)
This piqued our interest because most of our previous analysis focused on the comment submission timestamps and their content and we didn't do a whole lot from this angle. The newest Gravwell release added the “eval” module which creates TREMENDOUS potential for detailed analytics in the pipeline. We only need a tiny bit of that power to do a more analytics on name re-use in the comments.
First, let’s look at the big picture on the names submitting comments. Over the course of the entire comment period, the total number of unique names are:
| May | 4806642 |
| June | 0108503 |
| July | 9470805 |
| August | 6736872 |
| Total | 21647641 |
tag=fcc json filers | regex -e filers ":\"(?P<name>.*)\"}" | count by name | count
The number of repeated names is fairly insignificant to the data, as a whole. While there are re-submitted comments, most of the bot submissions were done in bulk or a series with unique names.
Let’s get a bit more data on the names being submitted and examine the surnames compared to what is expected.
| Looking at a count of all surnames being submitted, we have a breakdown of: | According to the US Census Bureau, the top surnames for the US are: |
|
* I started the analysis from the couch after coming out of a turkey coma, hence the mobile screenshot. |
Smith Johnson Williams Brown Jones Miller Davis García Rodríguez Wilson |
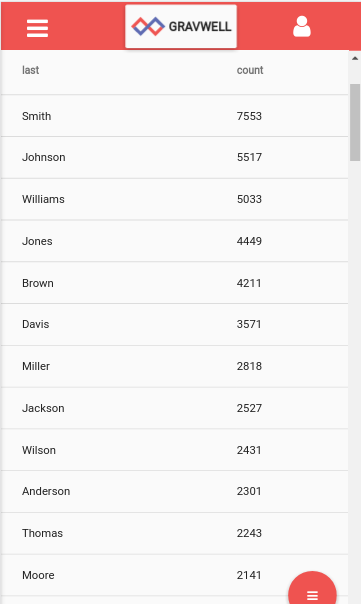
tag=fcc json filers as filers | regex -e filers ":\"(?P<name>.*)\"}" | regex -e name "(?P<first>\S+).* (?P<last>\S+)" | count by last | sort by count desc | table last count
Interestingly, the distribution matches almost perfectly. This is unusual in real data but we are talking about 22 million samples so perhaps it's not that farfetched. What this tells us about bot activity is that the personal information being submitted was obtained about real individuals. For example, a bot herder could be submitting using names stolen out of the Equifax data breach. We aren't currently in possession of any breach data to make a comparison, but it would be quite interesting.
We can add a few more data points to make the records more unique. If we count on unique name + address + zip code combination, we get the following results:
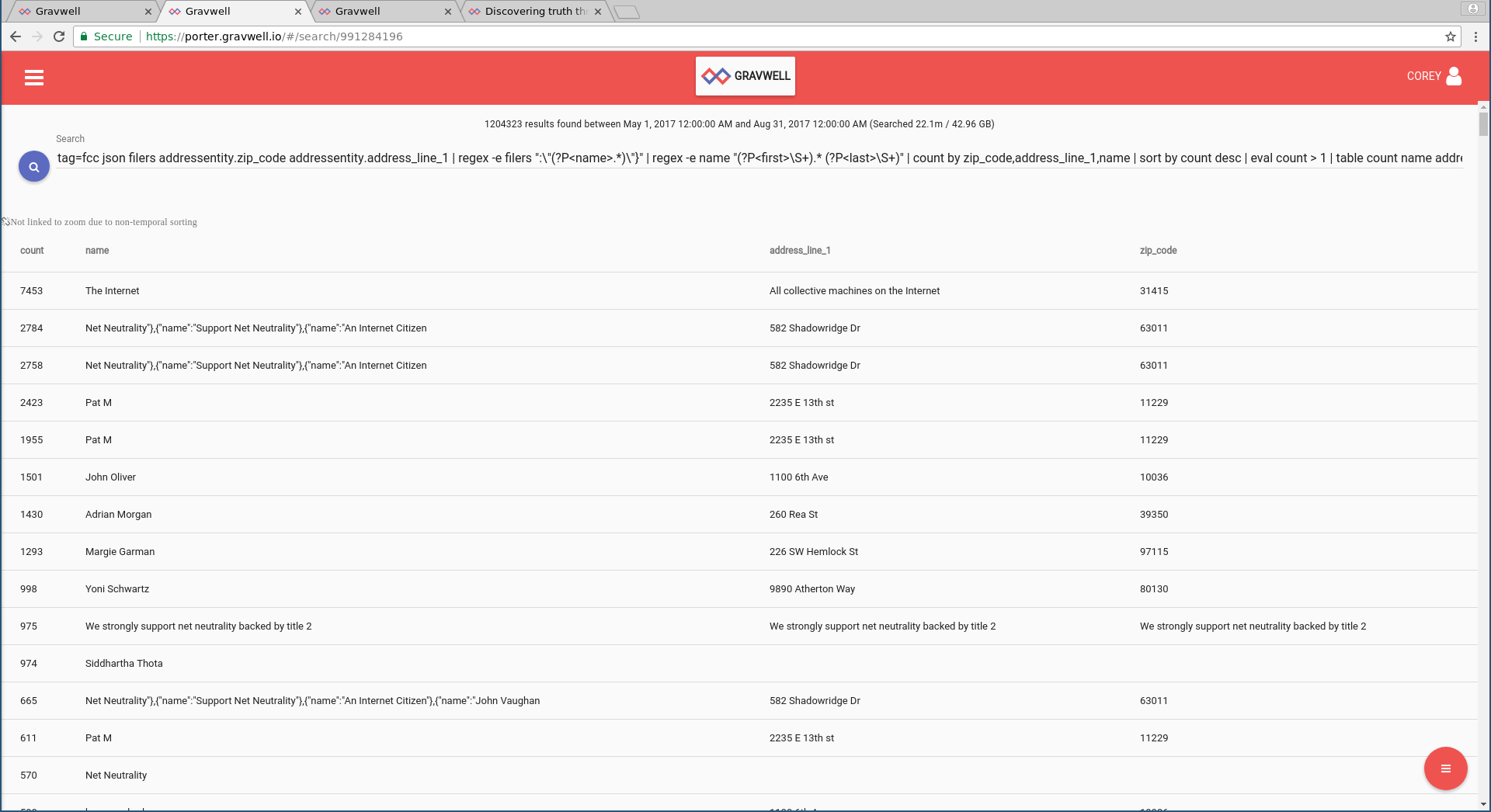
tag=fcc json filers addressentity.zip_code addressentity.address_line_1 | regex -e filers ":\"(?P<name>.*)\"}" | regex -e name "(?P<first>\S+).* (?P<last>\S+)" | count by zip_code,address_line_1,name | sort by count desc | eval count > 1 | table count name address_line_1 zip_code
We invoke the new eval module to filter out any records that have a count of 1 (i.e. unique combos). At the top of the screenshot you’ll see “1204323 results found between May 1, 2017 12:00:00 AM and Aug 31, 2017 12:00:00 AM (Searched 22.1m / 42.96 GB)”. So of the 22.1m comments, 1.2m name + address combinations are repeated more than once.
Summing up the total repeated name + address combinations results in a total count of 10934174. In other words, around HALF the comments came from repeated use of those 1204323 individuals. Put yet another way, 1.2 million unique name + address + zip codes were used multiple times, for a total of 10.9m "suspect" comments.
tag=fcc json filers addressentity.zip_code addressentity.address_line_1 | regex -e filers ":\"(?P<name>.*)\"}" | regex -e name "(?P<first>\S+).* (?P<last>\S+)" | count by zip_code,address_line_1,name | sort by count desc | eval count > 1 | sum count
Final Thoughts
Our mantra is always to build on the truth found in the data. Whether that's a political discussion with family around the holidays or a meeting with the CISO to make policy decisions on security. Having the ability to ask questions of the data and to obtain actionable knowledge is paramount to good decision making. Gravwell turns data into intelligence.

Happy Thanksgiving from all of us at Gravwell to you and yours. We're thankful for YOU.