Parts of a Query
A short but important post today - we’ll go over four easy tips and tricks for improving your search performance by putting a little thought into how you structure your query. But first, a little primer on the parts of a query.
A Gravwell query represents a dataflow. Data entering one module gets modified, dropped, enriched, etc., and is propagated to the next module in the query.
For example:
tag=gravwell syslog Severity Message | count Message by Severity | chart count by Severity
This query has four components:
tag=gravwell- Read from the "gravwell" tag, which resides in a well on disk based on your configuration.syslog Severity Message- Extract from entries read from the "gravwell" tag the "Severity" and "Message" fields, asserting that the data is syslog.count Message by Severity- Create a count of entries, grouped by the "Severity" EV generated in the previous module.chart count by Severity- Create a chart of the count created in the previous module.
The most important observation when creating a query is that all data emitted by a module is seen by the next module in the pipeline. If we can limit or filter data early in a pipeline, we can dramatically improve the performance of the overall pipeline simply by removing the amount of data processing required.
Extract first
tag=default json foo==barThis query uses the json module to extract a field “foo” from the default tag. Additionally it filters down to just values of “foo” that equal “bar”. With data acceleration, the json module can inform the indexer that it will be filtering for the value “bar”. The indexer in turn can only extract entries containing this word.
There are ways, however to prevent Gravwell from inferring this. First, let’s look at a very bad example:
tag=* grep bar | alias DATA myData | json -e myData foo==bar baz | stats count(foo) | table countThis query (poorly) counts the number of entries that are valid JSON with a member "foo" that contains the contents "bar". There are a number of things about this query that decrease performance:
tag=*- This reads from all tags on the system. You likely do not need to do this. Instead, make sure you only query tags you expect to extract data from (such as tag=json).grep bar | alias DATA myData- These two modules filter data down to just those that have the bytes "bar" anywhere in the DATA portion, and then alias the DATA to an enumerated value. The filter in the following JSON module already does this, and can take advantage of indexer acceleration if simply used directly (and without the -e flag). Additionally, thegrepmodule does not support acceleration.json -e myData foo==bar- This looks like our original example, but it’s extracting from an enumerated value, not from a tag directly. This prevents the indexer from engaging acceleration.
A much faster and equivalent query would be:
tag=jsonData json foo==bar | stats count(foo) | table countIn this rewritten version, the key optimization is that the json module can hint to the indexer that it is looking for the keyword "bar". Then, if the indexer has acceleration data for that tag, only entries containing "bar" will be sent to the pipeline. This greatly reduces pipeline processing overhead.
There are a number of data acceleration engines and extraction modules that allow you to tailor what and how data is indexed (for example json vs pcap). For more information on acceleration, see the acceleration documentation.
Minimize extractions
tag=pcap packet eth.SrcMAC eth.DstMAC eth.Type ipv4.IP ipv4.Payload tcp.Port | max Port | table maxThe above query uses the packet module to extract 6 fields and only uses one (Port). Gravwell performs a best effort optimization at parse time to eliminate unused extractions in modules, but there are several scenarios where the extractions may still take place. Therefore, in order to reduce burden on the packet module, which in this example not only has to extract the packet data, but also perform type assertions on MAC addresses, IP addresses, and integers, you can rewrite the query with just the necessary extractions for the end result:
tag=pcap packet tcp.Port | max Port | table maxtag=default json UUID foo | lookup -r data foo bar baz | eval UUID=="cd656e75-d54d-4e80-ac13-bc77abdde0ad" | tableThe above query extracts json data, performs some processing on every instance of "foo", and then filters the data down to just those entries with a specific UUID that was extracted in the first module. This query is potentially very costly, as the indexer must retrieve every record in the "default" tag for the given timeframe, and the lookup module must perform additional data lookups. If we moved the filter to the json module instead, we could reduce the overhead considerably, especially if acceleration is enabled on the default tag. By moving the filter to the beginning of the query, we allow the indexer to perform retrieval optimizations on disk, and we minimize the number of entries sent down the pipeline.
An optimized version of this query would look like:
tag=default json UUID=="cd656e75-d54d-4e80-ac13-bc77abdde0ad" foo | lookup -r data foo bar baz | tableIn this query we filter first (and possibly enable acceleration if it’s enabled on the default tag), and minimize the data sent to the later modules to just entries we want.
Put condensing modules as late in the query as possible
Some modules require knowledge of all data passing through that portion of a pipeline in order to function. For example:
tag=default json value | table valueThis query simply asks all indexers to extract "value" from JSON data and show it on a table. This is a simple operation to perform in parallel because the indexers don't need to coordinate or share any data -- they simply send their results to the webserver to be rendered.
Now consider:
tag=default json value subxml | stats mean(value) | xml -e subxml Name | stats unique_count(Name) | table mean unique_count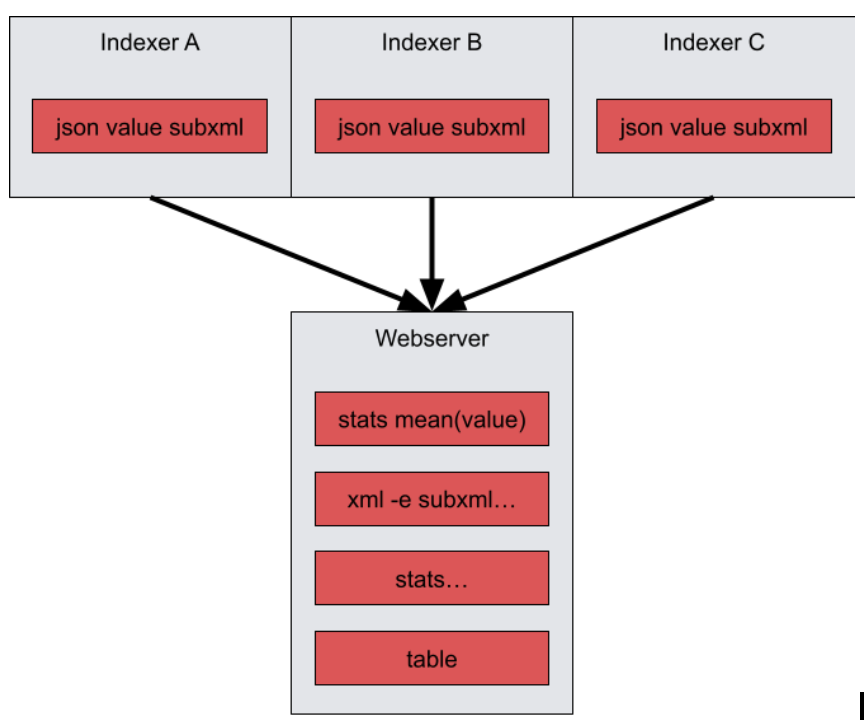
This query performs a mean operation on "value" early in the pipeline. In order to calculate the mean, the stats module must have all instances of "value". This causes the query to "condense" at the stats module, meaning that the indexers no longer run in parallel, but instead send their data to the webserver after extraction, and the remaining query is performed on the webserver. It is best to put condensing modules as late in a query as possible so that indexers can continue to run in parallel. Since no other modules except for table depend on the mean, we can simply rearrange this query. Additionally, the stats module can perform multiple operation in a single invocation:
tag=default json value subxml | xml -e subxml Name | stats mean(value) unique_count(Name) | table mean unique_count
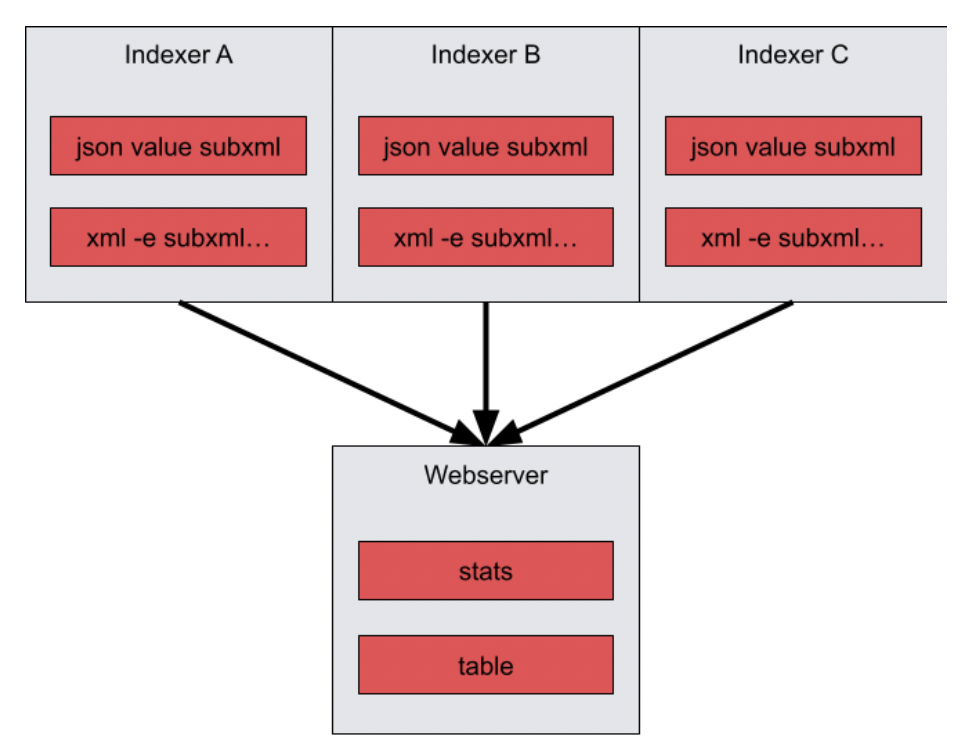
In this form of the query, the indexers perform the extractions locally at each indexer, and then send the data to the webserver to perform the stats operations.