Greetings from the R&D department of Gravwell! We’re here today to show you a sneak peek of one of many features coming in our next release, Gravwell 4.2.0.
Gravwell 4.2.0 introduces a powerful new tool to help both the new and seasoned user get started with new data, regardless of its structure, without ever having to touch the keyboard -- Data Explorer!
It’s easier to just show you, so let’s dive in! We’ll start with some JSON encoded DNS data taken from a Gravwell CoreDNS Ingester. It’s already indexed and ready to query, so we just have to fire up Data Explorer.
When we start Data Explorer and point it at our DNS tag, it automatically suggests an extractor based on the type of data. In this case, Gravwell suggests (with high confidence) that the data be extracted with the “json” module.

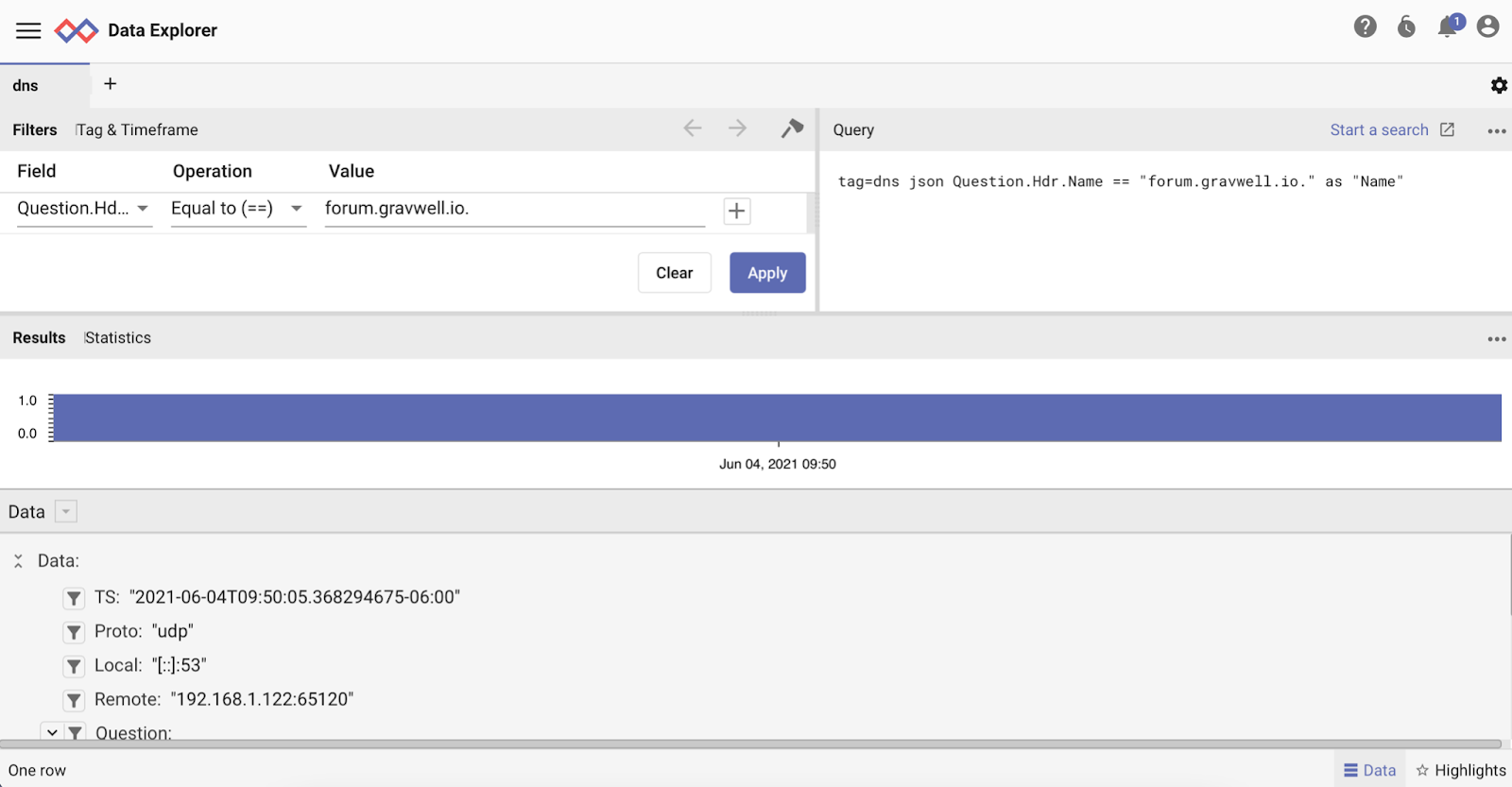
When we select this extractor, we’re taken to the Data Explorer view, which has a breakdown of all JSON fields pre-extracted along with the current query, filters, and an overview. If we click on an automatically generated extraction, for example “Question.Hdr.Name”, we can apply the field to our list of filters.

When we apply a filter, the query is automatically updated with the filter, and the dataset refreshed with the filter applied, all without having to touch the keyboard or know anything about our data!
Data Explorer can even work with existing auto extractors. In the screenshot below, we have CSV data with an AX installed that extracts the first 3 columns as “foo, bar, and baz”. Our CSV dataset contains more than 3 columns, and Data Explorer shows us those too. If we add filters in this view, Data Explorer will build a query with both the “ax” and “csv” modules already pipelined together!

Data Explorer makes it easy to dive into new data, regardless of the data type, and will be available with the upcoming Gravwell 4.2.0 release. If you want to get started with Data Explorer now, checkout our Gravwell Beta Program. Stay tuned for more Gravwell sneak peeks!
For more information, contact info@gravwell.io.