Overview
We are pleased to announce the immediate availability of Gravwell 4.2.0, code name Voyager. The 4.2.0 Voyager release marks a major milestone for us in reducing the complexity of interacting with the query language while also enabling highly optimized data storage and indexing performance. Long story short, we sharpened both sides of the axe.
Data Explorer
The clear star of this release is Data Explorer, a new system which automatically identifies the format of data and applies structure when possible. The data explorer system makes it much easier to drop into a new data environment and explore available fields, formats, and processors. When you first click on Data Explorer you will be presented with your list of tags. Click a tag and if there is no existing format association, Gravwell will make some intelligent guesses and present you with options. For example, here is what Gravwell presented to me when I first loaded up CoreDNS data.

A few things COULD work, but Gravwell was very confident that this is JSON, hence the 100% confidence level. I select that auto extractor and I am off, clicking my way through CoreDNS JSON data.
Data Explorer is an intelligent interface for rapidly identifying structure on data and assigning extractors that can help render data into more usable forms. Binary formats like Netflow and IPFix are easy to navigate, and building out the base filtering queries for those types becomes much easier.
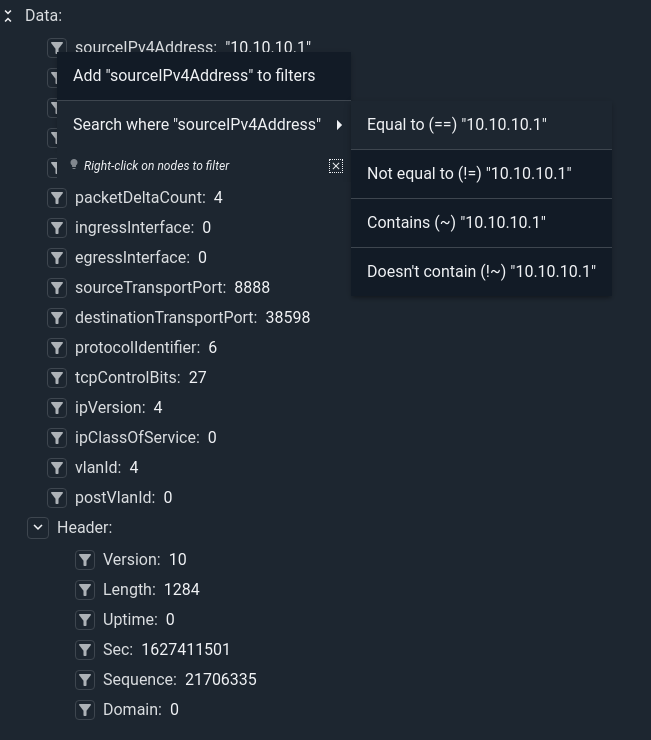
The little filter icons let you rapidly dig into fields and down-select. As you apply filters, the system will refresh the query and provide a new result set. This lets you click your way into a subset of data and then pivot out for more advanced querying. The filters can also be adjusted using the drop-down menu and editors. This means you can tweak your query filters and see how the resulting query is rewritten. We wanted to make sure that the power of the query language was never hidden from users, so even though you may be clicking your way to glory the query is always presented and available for use. It's a great way to get used to the query syntax and filtering without diving headlong into the full language.
Data Explorer also has another trick up its sleeve that is subtle but important: preview mode queries. When using Data Explorer, each query is fired in a "preview mode" which means you don't have to specify time ranges, instead you are telling Gravwell "just go find enough to make sense." Behind the scenes Gravwell identifies the type of renderer you are using and acquires enough data (filters included) to present a reasonable picture. Looking at the raw entries, we will get about a thousand entries; a chart pulls enough to show a decent curve; maps have enough points so a human gets the idea, and so on. You don't have to worry when the data is, Gravwell will figure that out and go get it. As a result you can click around and your time range will dynamically expand or shrink as needed to present usable data. When you pivot out of Data Explorer you can then specify a time range and carry on as normal.
Query Studio
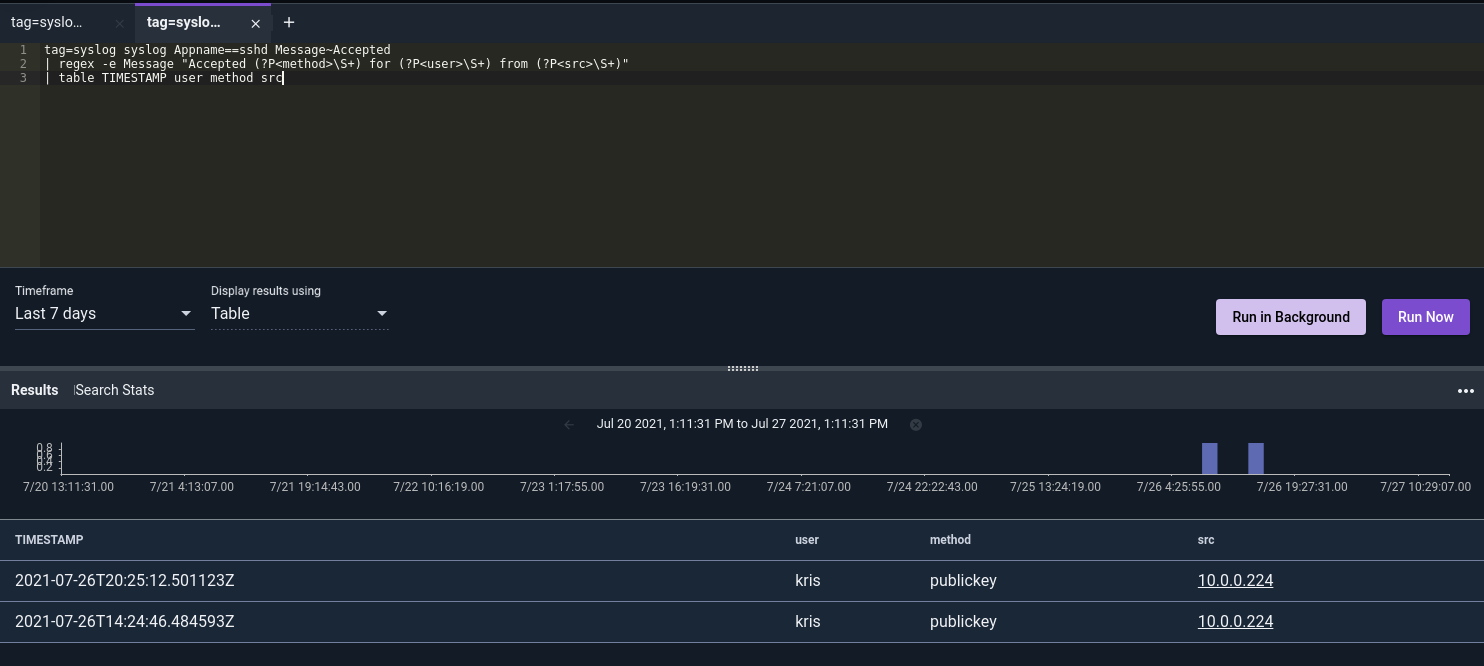
A common theme we see from users when they are onboarding new data, investigating an issue, or just trying to figure out a crazy data structure (or complete lack thereof) is that they have multiple windows open, constantly flipping back and forth between some nuanced representation of a data set and the view of the raw underlying data. As a result we have decided to bring the Query Studio system to the front and center. Query Studio is a refinement on the original query window which can display multiple tabs within the same view port while also attaching notes, labels, and rapidly cloning & refining a query. Query Studio is going to be growing a lot in the future and will eventually become the primary query interface into Gravwell.
Per Tag Acceleration
The heaviest hitter on the backend system is our new per-tag acceleration capability. With the new system we have made it much easier to really hone the performance of specific tags and/or categories of tags; now, administrators can deploy useful defaults and then fine tune acceleration for specific tags. A new clean installation of Gravwell now packs a decent baseline set of well definitions, plus some fine tuned accelerator definitions for common data types. You may notice that the Accelerator definitions can be in separate files; this means you can develop them independently and then just import them for easier management. Accelerator definitions also work with tag wildcards, so you can say "do X for zeekconn and Y for zeek*". The zeekconn tag will get the specific accelerator definition and everything else that matches zeek* will get the other. Full documentation on per-tag accelerator definitions is available here.
A data source that really shows off the new system is Zeek. Zeek can provide a tremendous amount of useful data: connection logs, DNS, software inventory, DHCP, and more. The multitude of plugins available also mean that the type and format of that data can change based on the deployment. With per-tag acceleration definitions, we can fine-tune the extremely high volume zeekconn, zeekfile, and zeekdns tags and then provide a reasonable default acceleration config for all the others. In other words, speed when you know what you are doing and flexibility when you aren't quite sure yet. As always, changing the accelerator definitions doesn't mean your queries need to change or you need to re-index anything--Gravwell just figures out what it needs to do with what it has.
New Modules
We are also happy to announce a few search modules. The anonymize module is extremely useful for taking potentially sensitive data and anonymizing it in a sensible way while also being type aware. For example, if you choose to anonymize IPs, it will provide randomized IPs that are consistent across the search. Anonymize makes it safer to provide exemplar data to colleagues, other business units, or even law enforcement without needing to show the real deal.
The other module is dns. How many times have you narrowed down your search to an IP only to then pivot out to a console and fire off a reverse DNS lookup to figure out what machine it actually is? The dns module can now do that for you directly in the query. BE WARNED, while we cache aggressively, if you attempt to do a billion reverse DNS queries on an enterprise wide flow set, one of two things will happen: I.T. calls with a very sad face, or they cut you off. Use the dns module with care.
Conclusion
Gravwell 4.2.0 Voyager release is an exciting moment at Gravwell. I could not be prouder of the development team. However, this is just one more step along the path of total data visibility--we have so much more in store! Limits suck and we are excited to show you what your data can reveal when you tear down those barriers.
