We are pleased to announce the immediate availability of Gravwell version 3.2.2!
This one got away from us a bit and probably should be a major release, there is just too much good stuff in here. I tried to convince the team that we should just jump to version 10, but as our GUI lead started choking and muttering something about C'est absurde we decided to stick with a point release.
This release has a ton of fixes and performance improvements, including:
- Significant performance improvements to our user land compression
- Faster replication recovery after node failures
- Quality of life improvements to Windows ingester deployment
- A whole host of GUI improvements
- A new search module
If you have an existing Gravwell installation using the Debian repository, just apt update; apt upgrade and be on with your day. Shell installers are available on our downloads page; Docker users, you know what to do.
As always, the full changelog is available on our docs page. Now lets get to the good stuff, GROK!
The grok Search Module
Gravwell is an unstructured analytics platform. We pride ourselves on the ability to ingest first and ask questions later. While there is a push towards structured logging which allows for much easier interaction, in the real world logs are all over the board. It is pretty rare for us to see a shop that has a uniform and strict logging structure across all their own applications, let alone across all their infrastructure. This means that we often have to fall back on blunt instruments to get good visibility and extract the data we need.
Enter the regular expression, regular expressions enable users to generate state machines that can extract fields from unstructured data at runtime. The Gravwell regex search module is hammer taped to a scalpel, a swiss army chainsaw if you will. You CAN accomplish almost anything with enough sweat and the right regex. However, regular expressions are hard to write, easy to screw up, and almost impossible to remember. THE book on regular expressions "Mastering Regular Expressions" by Jeffrey Friedl is 544 pages long. I have books that cover entire computing languages that aren't that long, and the regular expressions book is compact and well written. They are just THAT complicated.
This is where grok comes in, grok uses abstracted tokens so that mere mortals can build out complex and readable regular expressions. Some other platforms use grok to tokenize input at ingest time, we use it to do extract fields at query time.
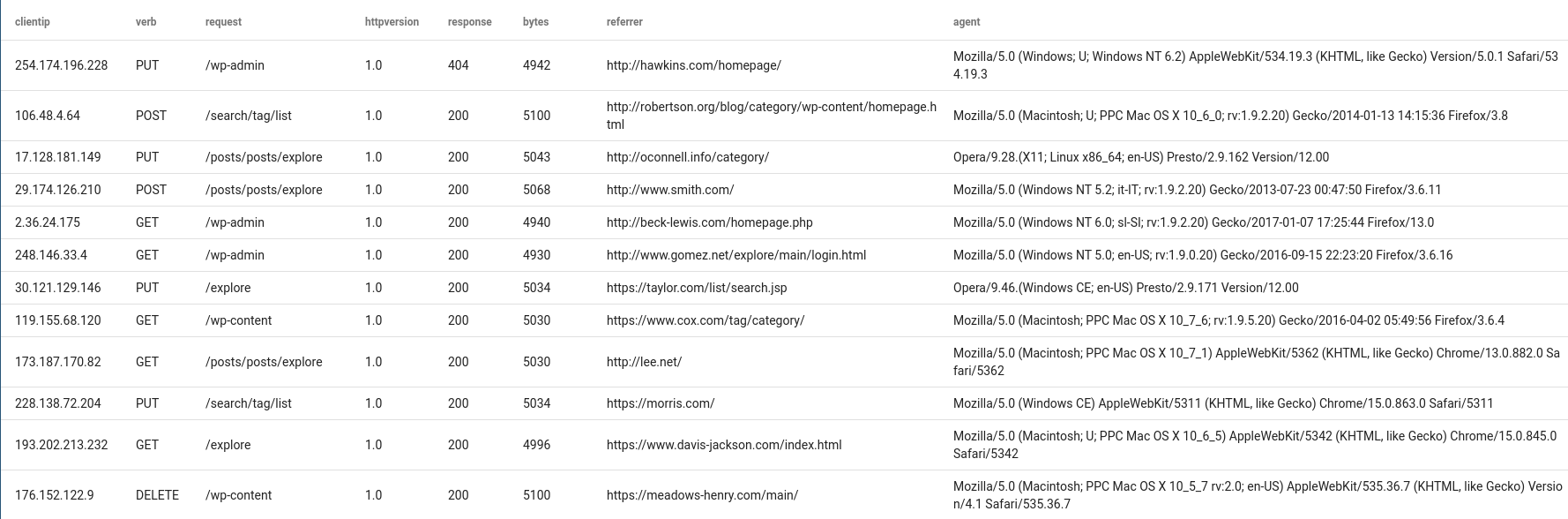
To really drive home how much power grok can provide, let's look at a complete regular expression designed to extract every field in an Apache Combined Access Log:
(?P<ip>\S+) (?P<remote_log_name>\S+) (?P<userid>\S+) \[(?P<date>\S+) ?(?P<timezone>\S+)?\] \"(?P<request_method>\S+) (?P<path>\S+) (?P<request_version>HTTP/\d+\.?\d*)?\" (?P<status>\d+) (?P<length>\d+) \"(?P<referrer>[^\"]+)\" \"(?P<user_agent>[^\"]+)\"
I consider myself above average when it comes to regular expressions, but that is barely readable. You might even say it's too hard to grok.
If we were to use grok, we could replace all that mess with one token:
%{COMBINEDAPACHELOG}
Grok is basically a macro system for regular expressions. Under the hood, grok identifies known tokens and performs a recursive expansion to generate a complete regular expression. Now, I could be abusive and show you the complete expansion sequence but no human alive would read past step 2 and actually pasting it into this blog post might actually get me fired...
To drive home just how powerful grok can be, the following query produces a nice table with every field extracted:
tag=apache grok "%{COMBINEDAPACHELOG}" | table
But Wait! There is more!
The Gravwell grok module ships with a standard set of verbs that cover the basics. The standard verbs are documented here, they cover things like numbers, words, hostnames, IP addresses, quoted strings, etc. Expanding on the set of grok verbs is as easy as uploading a resource. We have published an all.grok file on the Gravwell github resources repository. The all.grok file contains over 450 extra verbs covering everything from Apache access logs to Redis and Nagios. Just upload the all.grok file as a resource named grok and the grok module will automatically incorporate them in subsequent searches.
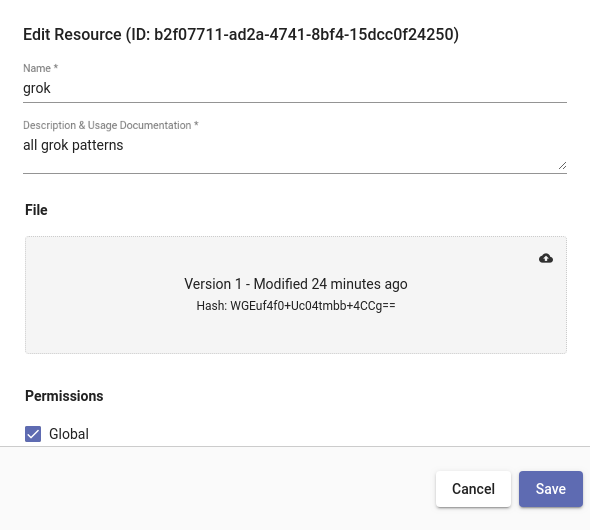
The grok module looks for the resource named grok by default, but if you have your own patterns for custom application logs you can add them to the all.grok file and re-upload the resource. Or you can create a new one and override the name with the -r flag. For example, if we wanted to run a query that handled a custom log structure using our own resource named internal the query would look like so:
tag=logs grok -r internal "%{APP2}" | table
Grok also supports inline filtering the same way that regex does, it's possible to hand filter expressions as an argument the expression. We could extend the above query to only show entries where a field matches some value:
tag=logs grok -r internal "%{APP2}" appname=="foo bar baz" | table
There Be Dragons
Grok dramatically simplifies the interface to regular expressions. Now the common man can piece together complex extractions using simple verbs. However, simplifying the interface to the tools also means that it is much much easier to create extremely complicated regular expressions without really knowing it. If we refer back to the COMBINEDAPACHELOG that could extract every field of an Apache log, we can see where the costs are.
The COMBINEDAPACHELOG verb generates an elaborate and strict regular expression, which means it can be slow. When wielding the power of grok it is always highly recommended to perform as much pre-filtering and down selection as possible first. The words module is a great candidate for trimming down the target log set while also invoking Gravwell's acceleration system. For example, let's run a few queries over 1 million Apache access logs. We will examine two queries that look for all Apache logs where the request method is POST and a response code of 404. First we will let grok do all the heavy lifting and filtering:
tag=apache grok "%{COMBINEDAPACHELOG}" verb==POST response==404 |
table
This query took about 59s to process the one million Apache access logs on a Ryzen 3700X, which is frankly terrible.
Now, lets look at using some other modules to trim down what grok actually has to look at, namely the words module (notice that we leave the inline filtering on grok in place):
tag=apache words 404 POST |
grok "%{COMBINEDAPACHELOG}" verb==POST response==404 |
table
Adding in the words module as a pre-filter allowed the query to complete in 370ms, that is nearly 200X faster.
So, grok is kind of like handing the fire control switch of the USS Iowa to Bob From Accounting. Bob is going to get some stuff done! Queue picture of Bob From Accounting analyzing your Apache logs:

It bears repeating, just because you CAN broadside a gopher problem doesn't mean you always SHOULD broadside a gopher problem. Wield the power of grok responsibly.
Closing It Out
Version 3.2.2 of Gravwell cleaned up the GUI, made replication faster, improved user land compression, and opened the power of regular expressions to us regular Joes. If you would like to see what is REALLY in your logs, checkout Gravwell with a free Trial license.

Once you see the power of Gravwell and are ready to stop of worrying about data caps and an archaic licensing scheme give us a call. We will show you how flexible ingest and a flat total cost of ownership can change your relationship with data analytics tools.