We understand that users may still use legacy solutions for various reasons: familiarity with the old tool, vendor lockin, or just a specific use-case they can't work around. For many in the Gravwell community, this legacy solution is Splunk--so in Gravwell 5.0.5, we set out to make their lives a little easier.
We've added a few Splunk integrations to Gravwell in 5.0.5--and they're free, too! As of Gravwell 5.0.5, you will be able to issue Splunk queries in Gravwell flows. If, instead, you want to get your data out of Splunk and into Gravwell, our new migration tool can help! More on that later...
Splunk Tokens
You'll need a Splunk authentication token to use either the Splunk flow node or the migration tool. You can find the page to generate tokens under the Settings menu:
From the Tokens page, generate yourself a new token and save the token string. You will not be able to reaccess it once you close the token creation dialog, so be sure to copy it!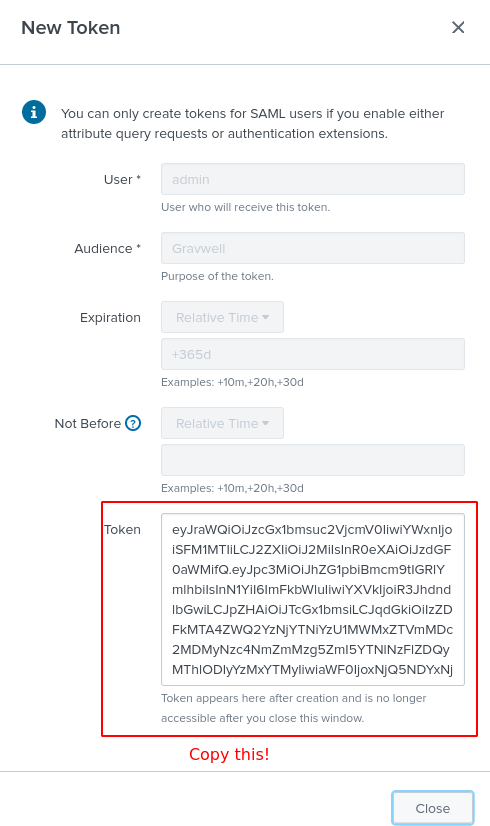
Note that Splunk's free license doesn't support tokens--unlike Gravwell's free Community Edition!
Splunk Queries in Flows
The Splunk Query node lets you run queries on a Splunk server from within a Gravwell flow. For instance, the flow in the screenshot below queries the Splunk server for all failed logins over the last day, uses the Text Template node to generate a simple table of the results, and then uses the Email node to send those results to an administrator.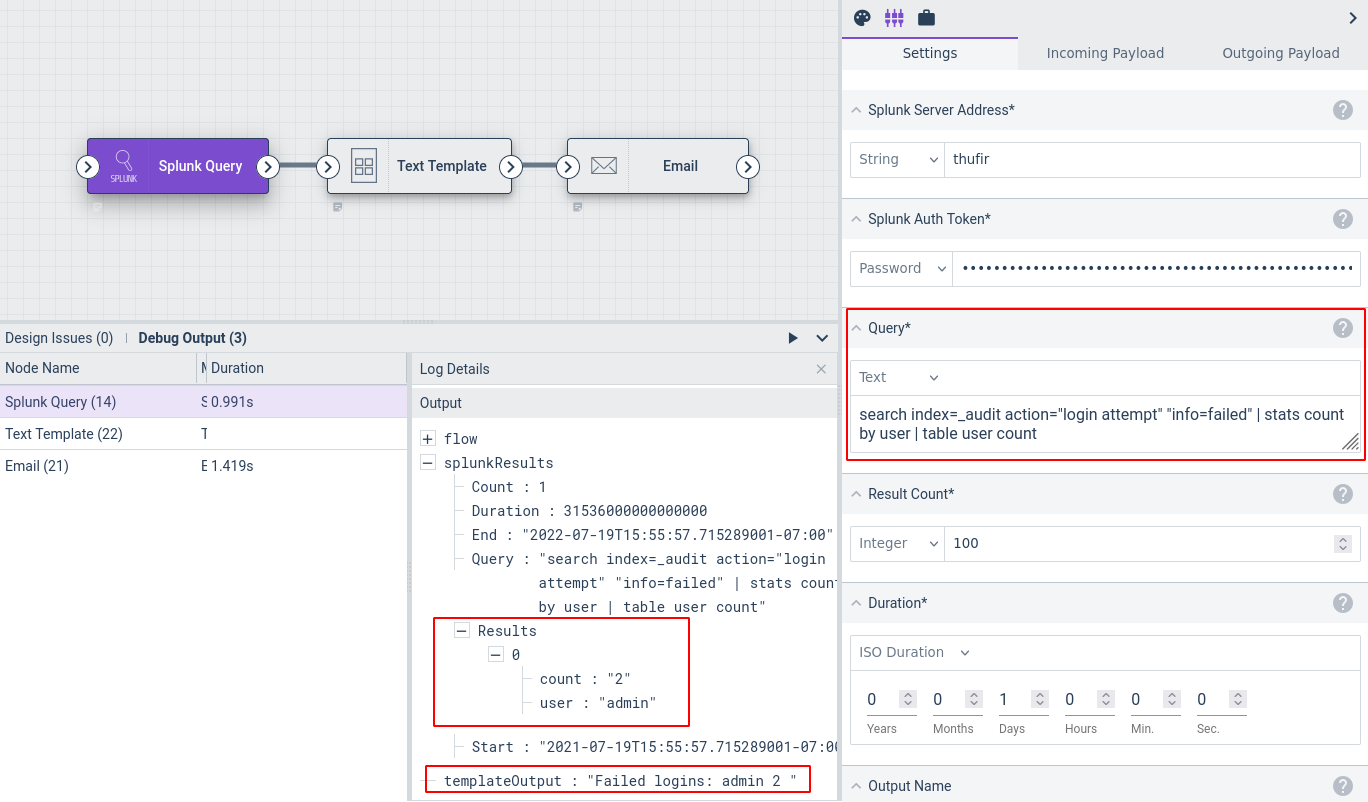
You can also just feed the results of a Splunk query node directly into an Ingest node, or encode them as JSON to send via the HTTP node, and so on.
Splunk Migration Tool
Gravwell offers a new user-friendly tool for migrating data out of Splunk and into Gravwell. It can also pull in data from files on the filesystem. It ships in the gravwell-tools package in our Debian and Redhat repositories, or you can get it from a stand-alone shell installer.
The migrate tool connects to one or more Splunk servers and pulls back a list of index + sourcetype combinations that exist on the system. You can then go through and pick which data you want to import, mapping an index + sourcetype pair to a Gravwell tag. The tool will then start pulling data out of Splunk and ingesting it into Gravwell. It supports multiple simultaneous import jobs, too, for better efficiency.
Conclusion
If you're not ready to fully ditch legacy solutions, we hope that our Splunk Query flow node may help you integrate "old and busted" (your Splunk cluster) with "new hotness" (Gravwell). Or, if you are ready to make the leap, our migration tool makes it easy to pull data out of Splunk and into Gravwell.
If you want to share what you built or have any questions, stop by our public Discord and chat with the team.