We are excited to introduce autoextractors with Gravwell version 3.0.2. Autoextractors make it easy for regex gurus and binary ninjas to generate extractions and share them in a portable format. Autoextractors can dramatically simplify the process of performing field extractions from unstructured data without complicated time-of-ingest data definitions; they can built and shared by ninjas and and used by us mere mortals.
For this post we will show how to build and install autoextrators; then we will show a few invocations to drive home just how much easier queries can be. Finally we will provide a few ready-to-roll autoextractors that can be used right now. Full autoextractor documentation is available at on the docs site.
Configuring Autoextractors
An autoextractor is globally available data definition which means that once defined, every user on the system (with access to a specific tag) can transparently access the extractions through the ax module. Extraction definitions are defined in files that must be resident on each webserver and indexer (typically in the /opt/gravwell/extractions directory). If you are using the Community Edition then you only need to push the autoextractor definitions to a single place.
Autoextractors allow for transparently invoking the functionality of other modules, allowing you to just reference the extracted names. As of version 3.0.2 there are autoextractors for the following search modules:
Autoextractor Definition Format
Autoextractor definitions follow the TOML format; each file can contain any number of extractions and there can be many files in the extraction directory. When starting up the webserver and/or indexer the service will scan the files located in the extractions directory and import each autoextractor definition. There are some rules that must be followed when defining autoextractors:
- Extraction definitions must be regular files, no symlinks
- Each extraction is bound to a single tag
- There cannot be more than one extraction per tag
- module, tag, and params values must be populated
- name, desc, and args values are optional
- Filters cannot be defined in autoextractors
- All Fields must be quoted
- Use backslashes to escape double quotes
- Use single quote for raw string to avoid double escapes
- Filter operators are determined by the module invoked by the definition
- Extractions cannot operate on enumerated values (no -e), only the raw data.
[[extraction]]
name=”humanname”
module=”supported_module” #here is a comment
desc=”Human friendly description”
tag=”tagname”
params=”arguments to the extraction module”
args=”flags and/or arguments for module”
Be sure to checkout the docs for complete configuration documentation.
User Autoextractors
Autoextractor definitions are “invoked” using the “ax” search module. The “ax” module uses the provided tags in the query to identify and invoke the appropriate extraction definition. If multiple tags are provided the “ax” module can and will invoke multiple extractions and apply them to the appropriate data based on tag.
There are some rules associated with enumerated values and how autoextractors process them:
- If no enumerated value names are provided, everything is extracted
- If all provided enumerated values have a filter operator, everything is extracted
- If a subset of enumerated values are provided, only those are extracted
Lets get on with some examples.
Regex
Lets start with a simple example where we use the “regex” functionality to extract and name all the fields in an Apache 2.0 combined access log. Like any good regular expression, at first glance it’s pretty vicious:
regex "^(?P<IP>\S+) (?P<ident>\S+) (?P<userid>\S+) \[(?P<timestamp>[\w:/]+\s[+\-]\d{4})\] \"(?P<method>\S+)\s?(?P<url>\S+)?\s?(?P<protocol>\S+)?\" (?P<resp>\d{3}|-) (?P<bytes>\d+|-)\s?\"?(?P<referrer>[^\"]*)\"?\s?\"?(?P<useragent>[^\"]*)?\"?$"
If we assume that our Apache combined access logs are coming in under the tag “apache” and we wanted to just extract every field and render them in a table, the query would be as follows:
tag=apache regex "^(?P<IP>\S+) (?P<ident>\S+) (?P<userid>\S+) \[(?P<timestamp>[\w:/]+\s[+\-]\d{4})\] \"(?P<method>\S+)\s?(?P<url>\S+)?\s?(?P<protocol>\S+)?\" (?P<resp>\d{3}|-) (?P<bytes>\d+|-)\s?\"?(?P<referrer>[^\"]*)\"?\s?\"?(?P<useragent>[^\"]*)?\"?$" | table
While the query functionality is pretty simple (extract the fields and park them in a table), the regular expression can make it pretty daunting. To simplify the query and reduce some of the cognitive overhead in handling the Apache combined access log, let’s build out an autoextractor definition:
[[extraction]]
name=”ApacheCombinedAccessLog”
desc=”Use regex to extract fields from an apache combined access log”
module=”regex”
tag=”apache”
params=’^(?P<IP>\S+) (?P<ident>\S+) (?P<userid>\S+) \[(?P<timestamp>[\w:/]+\s[+\-]\d{4})\] "(?P<method>\S+)\s?(?P<url>\S+)?\s?(?P<protocol>\S+)?" (?P<resp>\d{3}|-) (?P<bytes>\d+|-)\s?"?(?P<referrer>[^"]*)"?\s?"?(?P<useragent>[^"]*)?"?$"
NOTE: we used a single quoted string for the params field so that we didn’t have to go through and escape all the double quotes.
Using the ax module we can then transform the original query to a functionality equivalent query:
tag=apache ax | table

We can even invoke some inline filtering; for example if we only wanted to see the access logs where the useragent contains the word “Windows” and the response code was not 200 we would issue the following query:
tag=apache ax resp != 200 useragent ~ Macintosh | table
The above query applies the filters and produces the following output:

Notice that every single extracted value was provided, this is due to rule #2. The enumerated values we provided all had filters which caused the ax module to process the filters and provide every enumerated value. If we add a non-filtered enumerated, value then only the specified enumerated values are extracted.
tag=apache ax IP url resp != 200 useragent ~ Macintosh | table

Here, because we supplied some non-filtered enumerated values the ax module only extracted the modules we explicitly specified. Behind the scenes, if you don’t actually use the enumerated values Gravwell fixes up your query so we don’t do work that isn’t needed; but if you are just firing at a table these little rules can help make the results a little more readable.
Slice
The slice module basically an opinionated scalpel, allowing us to slice and dice binary data formats and cast the results to types that make sense. Slice is difficult to use, at best. Operators will basically need to be protocol and format reverse engineers, but when you need it you need it. Autoextractors can make it possible for us to leverage the work of ninjas without getting bogged down in the nitty gritty details.
For this example we are going to tease an upcoming blog post called “Brewing with Gravwell” where we build out an end-to-end data collection and control platform that monitors the fermentation, conditioning, and control for a homebrew setup. One of the data providers is a little open source control system that ships data in a kind of convoluted (but highly efficient) binary format.
We won’t get too deep into the data provider and its format, but we turn this:
tag=keg slice uint16be([0:2]) as tag float32be([18:22]) as temp [22:] as name | eval tag==0x1200 | mean temp by name | chart mean by name
Into this:
tag=keg ax | eval tag==0x1200 | mean temp by name | chart mean by name
And get this:
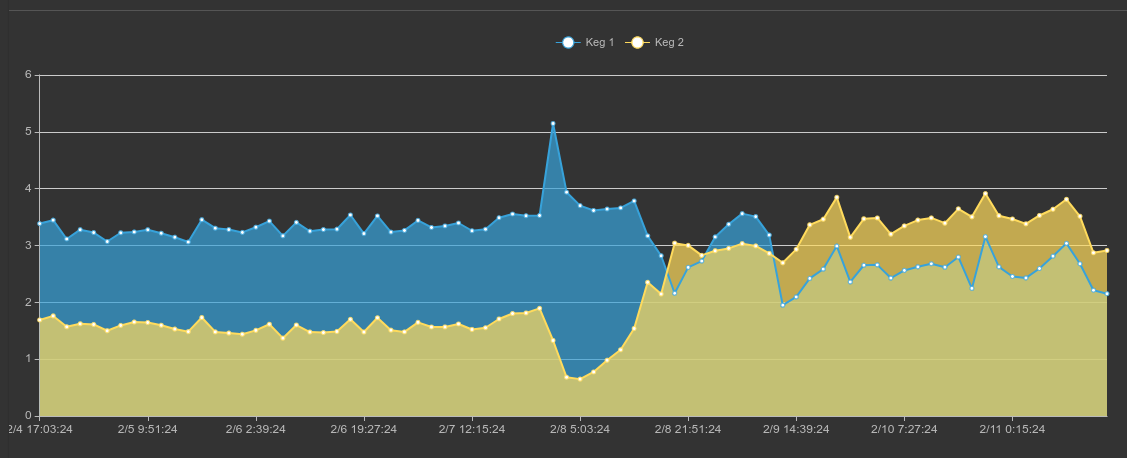
Keg 1 is a tasty Brown and Keg 2 is a crisp and lean Citrus Lager; but let’s leave those details for the next post.
Conclusion
We showed how to use autoextractors to dramatically simplify interacting with data that is unstructured, doesn’t have a dedicated processing module, or isn’t self-describing. Using the ax module we were able to perform otherwise complicated data extraction and fusion tasks without having to remember complicated regular expressions or binary data formats. The autoextractors allow for defining structure based on tag without the added complexity of time-of-ingest field enumeration and the flexibility to iterate and improve.